
No Limitation
[Deep-Learning] 2D Convolution operation 본문
많이 사용하는 convolution 연산이지만
조금 더 개념적으로 다루어보고자 블로그 글을 정리합니다.
Justin Johnson 교수님의 미시건 강의 'Deep Learning for computer vision Lecture 7'을 참고하였고 JINSOL KIM님의 블로그 포스팅 (https://gaussian37.github.io/dl-pytorch-conv2d/) 을 참고하였습니다.
일반적으로 convolution 연산을 공부하는데 필요한 개념적인 부분 ( 필터, stride, padding 등등의 개념은 정리하지 않겠습니다. )을 안다는 가정하에 포스팅을 작성하였습니다.
아래 그림과 같이 input과 stride, padding과 filter 사이즈가 주어졌다고 가정해보겠습니다.

Input의 채널은 3이고 64x64의 이미지임을 알 수 있고 stride는 1, padding은 일반적으로
kernel 혹은 filter 의 size에 따라 결정되는 것이 일반이라 이 경우 (5-1)/2로 2로 설정하였습니다.
다음으로 filter 인데요, filter의 경우는 보통 input의 채널과 동일하게 가져가기 때문에 3을 했고 size는 5로 하나의 filter는 3x5x5 의 사이즈로 구성되는데 이 경우 6개의 filter를 사용한다고 하면 총 6x3x5x5로 구성이 됩니다.
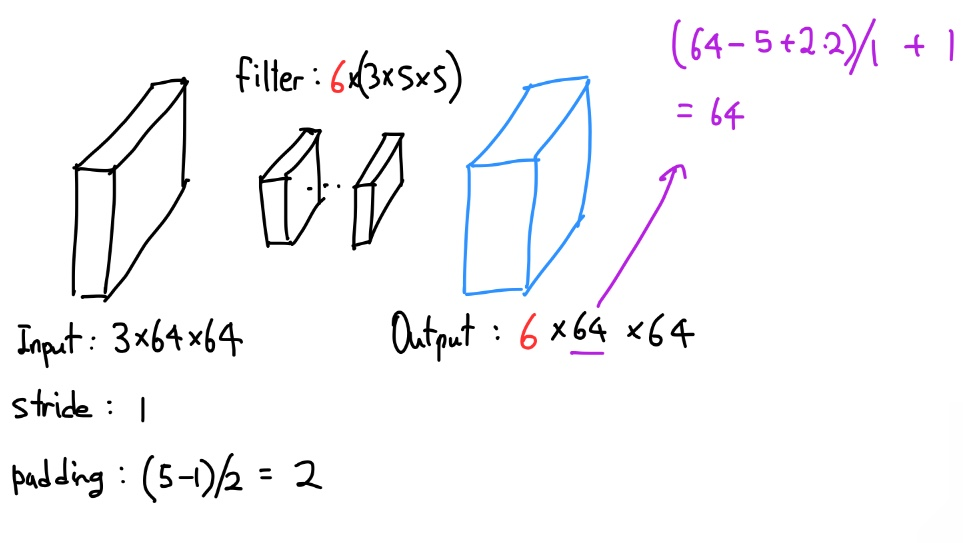
그렇다면 이제 output의 shape은 어떻게 될까요? output의 경우 filter의 갯수를 차원으로 가져가고 output의 shape의 경우는
( Input - Filter + 2*padding )/Stride + 1
형태로 구성이 됩니다. 하나씩 대입해보면 동일하게 64가 나옴을 알 수 있습니다. stride=1이기 때문에 실제로 downsampling이 발생하지 않았습니다.

이렇게 될때 가중치 매트릭스의 shape은 어떻게 구성될까요? 이는
filter의 수 x input shape x filter shape x filter shape
으로 구성이 됩니다.
Bias vector의 경우도 filter의 수 size의 vector가 되구요.
따라서 이를 한 눈에 보기 좋게 정리하면 다음 슬라이드와 같습니다.

그럼 이제 실제로 pytorch를 사용해서 어떻게 이것이 적용되는 지를 확인해보겠습니다.
우선 필요한 라이브러리를 불러오고
import torch
from torchvision import datasets, transforms
import torch.nn as nn
import torch.nn.functional as F
실제 딥러닝을 학습할 때는 배치 사이즈를 주는 경우가 존재하기에 배치를 16으로 줍니다. 데이터는 MNIST를 사용하겠습니다.
batch_size = 16
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(
root = "datasets/", # 현재 경로에 datasets/MNIST/ 를 생성 후 데이터를 저장한다.
train = True, # train 용도의 data 셋을 저장한다.
download = True,
transform = transforms.Compose([
transforms.ToTensor(), # tensor 타입으로 데이터 변경
transforms.Normalize(mean = (0.5,), std = (0.5,)) # data를 normalize 하기 위한 mean과 std 입력
])
),
batch_size=batch_size,
shuffle=True
)이제 이렇게 구성이 될 경우, 하나의 배치에 대한 input shape은 다음과 같습니다.
image, label = next(iter(train_loader))
print(image.shape, label.shape)
## batch = 16, input channel = 1, input height = 28, input width = 28torch.Size([16, 1, 28, 28]) torch.Size([16])
그럼 이제 실제로 Convolution 연산을 적용해보겠습니다. 구현은 torch.nn.Conv2d 함수를 사용하였고 필수적으로 넘겨야 하는 파라미터는 in_channel, out_channel, kernel_size 값입니다.
m = nn.Conv2d(
in_channels = 1,
out_channels = 20,
kernel_size = 5,
stride = 1,
padding = 2
)
이제 이를 놓고 연산을 돌리면 어떻게 될까요?
우선 output shape부터 살펴보게되면,
output은 우선, batch 16은 그대로 가져가게 되고 kernel size가 5이므로
padding 값은 => (5-1)/2 = 2가 됩니다.
그러면 output은 우선, output channel은 20으로 주어졌고, shape은 주어진 값을 활용하면
( 28 - 5 + 2*2 )/1 + 1 = 28이 됩니다.
따라서 input을 넣은 output은 다음과 같이 구성됩니다.
m(image).shapetorch.Size([16, 20, 28, 28]) ## batch = 16, output channel = 20, input height = 28, input width = 28그리고 마지막으로 weight matrix 구성도 구해보면

다음처럼 구성이 되어야 하기 때문에 20x1x5x5로 구성됩니다.
m.weight.shapetorch.Size([20, 1, 5, 5]) ## output channel = 20, input channel = 1, kernel height = 5, kernel width = 5
'ML & DL & RL' 카테고리의 다른 글
| [Deep Learning] Activation function & Weight Initialization & Regularization (0) | 2022.10.18 |
|---|---|
| [Deep-Learning] 나만의 CNN 구현해보기 실습 (1) | 2022.09.30 |
| [Deep learning] Sequence Modeling (0) | 2022.09.22 |
| [ Computer Vision ] Object Detection - RetinaNet & EfficientDet (2) | 2022.07.09 |
| [ Computer Vision ] Object Detection - SSD & YOLO (0) | 2022.07.02 |



