
No Limitation
[Deep learning] Sequence Modeling 본문
본 포스팅은 카이스트 데이터사이언스 대학원 박찬영 교수님의 '지식서비스를 위한 기계학습' 강의 자료를 바탕으로 제작되었습니다.
이 외에도 다양한 책과 블로그들을 참고하였습니다.
Reference는 포스팅 마지막 부분에 추가하겠습니다. 모두 너무 좋은 글들이니 참고하시면 좋을 거 같습니다.
시작하며,
최근 딥러닝 이론 공부를 많이 미루고 있다가, 최근 영상을 다루는 영역을 연구하면서 자연스럽게 따라오는 친구들인 sequence modeling에 대해 다시 공부할 기회를 갖게 되었습니다. 이전에 공부한 영역이지만 자연스레 잊히면서 정리의 필요성을 느끼게 되었고 이번에 감사하게도 정리하게 되었네요.
이번 포스팅은 Sequence Model의 기본이 되는 Recurrent Neural Net (RNN)을 기반으로 이들의 학습 방법과 이의 다양한 variant들, RNN의 한계점들과 그들을 극복하기 위한 Attention과 LSTM 중심으로 설명을 할 예정입니다.
RNN Basic
일반적으로 neural net 구조에서 한 input을 넣게 되면 그에 대응하는 하나의 output이 나오게 됩니다. 하지만 real world에서는 꼭 그렇지 않은 task들도 존재하게 됩니다. 예를 들면 Image2Text 같은 것은 이미지를 넣으면 text를 도출하는 형태로 그 데이터의 형태나 구조가 다를 수도 있고 길이도 다를 수 있습니다. 이러한 데이터의 input과 output의 크기가 다를 수 있다는 아이디어의 기초한 방법이 바로 RNN입니다. 크게 다양한 아키텍처들이 있는데 대표적으로 아래 그림과 같습니다.

일단 일반적인 neural net은 one-to-one 형태를 따릅니다. 하지만 그 외의 경우는 모두 RNN 구조를 기반으로 동작하죠.
처음으로 One-to-many 아키텍처를 살펴보겠습니다.

말 그대로 하나의 입력이 들어오면 sequence의 output이 나오는 형태인데 대표적인 예시로 'Image Captioning'을 들 수 있습니다.

다음으로는 Many to one setting이 있습니다.

예시로는 sentence classification, multiple-choice question answering, semantic-analysis 등을 들 수 있습니다.

다음으로는 Many-to-Many 케이스로, sequence 입력을 받아 sequence 형태의 output을 도출하는 구조입니다.
가장 많이 연구가 되고 있는 분야며 대표적인 예시로는 machine translation, video classification, video captioning, open-ended question answering 등이 있습니다.
특별히 여기서는 2가지의 variant가 존재하는데, 첫 번째는 모든 sequence를 입력으로 전부 받은 다음, output을 산출하는 방법이 있습니다.

특별히 이 아키텍처를 'Sequence to Sequence'라고 부르며 기계 번역의 기초 모형인 Seq2Seq이 대표적인 예시입니다.

두 번째 예시는 앞 예시와 다르게 sequence의 입력과 출력을 동시에 진행하는 방법으로, 구체적인 예시로는 Tracking, Early action detection, POS tagging 등이 있습니다.

그렇다면 왜 이러한 one-to-many, many-to-one, many-to-many 같은 task를 왜 일반적인 MLP로는 수행이 어려운걸까요?
우선 MLP는 sequence를 모델링할 수 없는 점에 있습니다.
- 고정된 input & output 설정
- temporal structure 대응이 어려움
또한 pure한 feed-forward processing을 거치기에 sequence에 필수적인 어떠한 'memory'나 'feedback' 과정이 없습니다.
feed-forward neural network 자체가 은닉층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향함을 의미하기 때문입니다.
따라서 RNN은 다음 역할을 수행하게 됩니다.
- Sequence data를 가장 잘 다루는 neural network 구조, long sequence input에 대응 가능
- 다양한 length의 sequence를 다룰 수 있다.
- 모형의 다른 part 별로 파라미터를 공유할 수 있다.
여기서 또 중요한 의미는 바로 세 번째 문장인데 그 의미를 구체화해보자면,
다음 문장이 주어질 때,

만약, 이 문장을 가지고 이 사람이 네팔을 언제 갔다왔는지를 맞추는 task를 수행한다고 해보겠습니다.
우선 이 각각의 토큰은 각자의 정보, 예를 들면 위치와 같은 그러한 파라미터들을 가지고 있습니다.

자 이 경우 일반적으로 다음과 같이 문장이 변한다고 하면

일반적인 MLP는 밑의 문장처럼 변할 때 2009의 의미를 파악하기 힘들지만 RNN은 다른 part 별로도 파라미터를 공유하기 때문에 저 2009가 위의 2009랑 같은 의미임을 파악할 수 있게 됩니다.
자 그렇다면 본격적으로 Recurrent Neural Network 의 구체적인 이론적 배경을 살펴보겠습니다.
Classical Dynamical System 동적 시스템
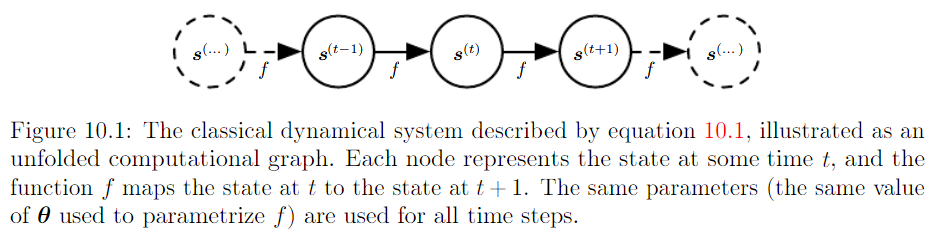
동적 시스템이란 출력이 현재의 입력 뿐 아니라 시스템의 상태 (과거의 입출력과 연계되는)에도 의존함을 의미합니다.
즉 현 시점 t의 출력 값은 현재의 state 만이 아닌 이전의 상태도 영향을 미친다는 것입니다.
만일 외부 신호 x가 t 시점마다 들어온다고 하면 우리는 바로 이 아이디어에 기초해서 computational graph를 구축할 수 있습니다. 아래 그림을 살펴보죠.

위 그림에서 h_t는 t 시점까지 stacked된 해당 정보들을 의미합니다. 물론 h_t는 fixed length vector이기 때문에 모든 정보를 다 함축할 수는 없기에 일부는 손해가 발생하는 "lossy summary"가 됩니다. 바로 이러한 아키텍처를 따르는 것이 RNN의 뼈대입니다.
자 그러면 이제 RNN의 중요한 디자인 패턴들에 대한 구체적인 예시들을 공부해보겠습니다.
(1) RNNs that produce an output at each time step and have recurrent connections between hidden units

우선 가장 기초가 될 수 있는 RNN 모형입니다. 매 time step 마다 input x가 들어오고 가중치 W는 다음 time step에 전달이 되는 방법으로 구축됩니다. 네트워크를 구성하는 코드를 다시 살펴보겠습니다.

가중치로 사용되는 매트릭스로는 input에서 hidden state로 넘어가는 U, hidden state에서 output으로 넘어가는 V, 그리고 hidden state에서 hidden state로 넘어가는 W가 존재합니다.
밑의 부분은 loss function을 보여주며, x1, ..., xt 까지의 input을 바탕으로 yt의 negative log likelihood 형태로 loss가 구성됩니다.
두 번째 패턴도 살펴보겠습니다.
(2) RNNs with recurrent connections between hidden units that read an entire sequence and then produce a single output

이 경우는 many-to-one의 형태의 구성을 의미합니다. time step 마다 output이 나오는 것이 아닌 last time-step에서 최종 output을 도출하게 됩니다.
마지막 패턴은 다음과 같습니다.
(3) RNNs that produce an output at each time step and have recurrent connections only from the output at one time step to the hidden units at the next time step

(1) 패턴과 비교했을 때 약간 구성이 다름을 알 수 있습니다. 기존에는 t-1 시점의 hidden state 값을 다음 t 시점의 hidden state을 구하기 위한 입력으로 넣었는데, 여기서는 t-1 시점의 예측값 σ를 t 시점의 hidden state를 구하기 위한 입력으로 넣었음을 알 수 있습니다.
이 방법의 경우 (1) 방법에 비해 less powerful하게 됩니다. 왜냐하면 hidden state에 있는 모든 가중치 정보들을 전달받는 것이 아니라 달랑 예측 scalar 값 하나만 전달 받기 때문입니다.
하지만 그럼에도 이 모형을 사용하는 이유는 이 학습 방법이 보다 효율적인 학습을 수행할 수 있기 때문입니다.
그런 측면에서 언급되는 것이 바로 'Teacher Forcing'인데, 이 방법은 Teacher Forcing과 같이 사용함으로써 curriculum learning이 가능하게 해주기 때문입니다.
이를 이해하려면 Teacher Forcing을 이해해야 하기 때문에 Teacher Forcing 개념을 살펴보겠습니다.
Teacher Forcing
일반적으로 RNN 계열 모형에서는 특정 시점의 output은 다음 단어의 출력에도 영향을 끼치게 되는데, 만약 초기 상황에서 이 output이 잘못 나오게 되면 거의 모든 문장에 안 좋은 학습을 끼치게 됩니다.
그래서 이전 시점에서 output이 잘못 나오게 되더라도 다음 step에 넘기는 것은 정답을 넘기는 것이 바로 Teacher Forcing, 즉 강제로 정답을 학습시키게 하는 것입니다.
"다음 step의 input으로 이전 값의 output이 아닌 원래 target이 input 값으로"
이 것이 teacher forcing의 핵심입니다.
하지만 단점도 존재하게 되는데요.
“만약에 학습 때 참고하던 데이터와 전혀 결이 다른 데이터가 inference 단계에 들어온다면?”
이러면 train data의 정답 만을 강하게 공부하던 모형은 전혀 다른 결의 테스트 데이터에 대해서는 잘 동작하지 못하는 문제가 발생할 것입니다.
그래서 우리는 이 문제를 풀기 위해 랜덤하게 정답과 generated value를 번갈아 가면서 다음 시점에 전달해주게 됩니다.
즉 이를 슈도 코드로 나타낸 예시가 있어서 공유하면
teacher_force = random.random() < teacher_forcing_ratio
input = trg[t] if teacher_force else top1 # 현재의 출력 결과를 다음 입력에서 넣기
# trg[t]는 실제 값, top1은 예측 값다음과 같이 랜덤하게 선택해서 다음 입력으로 넘기게 됩니다.
그리고 바로 저 generated value를 넘기는 경우가 바로 (3) 패턴에 해당하게 됩니다.
그리고 이러한 방법이 더 잘되는 이유는 이 방법이 바로 'Curriculum learning'이기 때문인데요,
이 Curriculum learning은 다음과 같은 개념을 의미합니다.
- 처음에는 모델한테 쉬운 샘플만 보여주다가 점차 어려운 샘플을 보여주는 것
- 이렇게 수행했을 때 학습이 더 잘됨
자 그럼 다음으로 이 RNN 에서의 Backpropagation은 어떻게 수행되는 것인지를 같이 살펴보겠습니다.
수식이 조금 많은 부분이라 복잡할 수 있지만 최대한 간단하게 정리해보겠습니다.
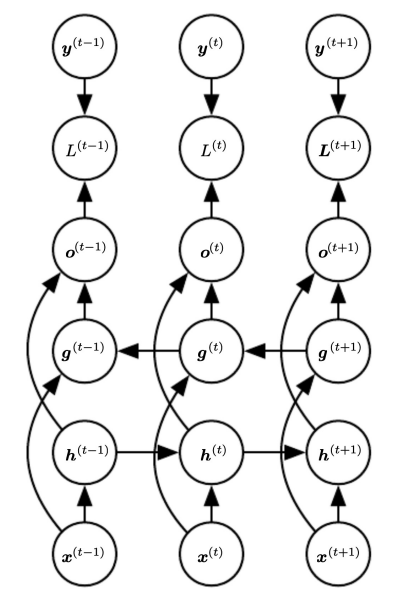
Backpropagation Through Time ( BPTT )
이 backpropagation은 다음과 같은 unfold computational graph와

다음 수식을 바탕으로 수행하도록 하겠습니다.

우선 L(3)에 발생한 loss를 바탕으로 backpropagation을 구해보겠습니다. 우선 처음에 구해야 하는 값은 아래 값입니다.

computational graph를 보면 이 부분과 같습니다.

해당 수식은 다음과 같이 전개됩니다.

맨 우측 항의 분모는 loss function인데, cross entropy 기반의 loss 의미하고 k는 class의 수를 나타냅니다.
양 분자 분모에 y_hat k의 값의 gradient를 붙여주면

다음과 같이 수식이 전개될 수 있습니다. 즉, 좌항과 우항을 y_hat k에 대한 gradient와 oi에 대한 gradient로 나누는 형태로 전개가 되었습니다. 다음 좌항의 log 미분을 수행해주고 나면 logx 의 미분은 1/x 이므로 다음처럼 수식이 전개됩니다.

그러면 우항을 보면

해당 term이 나오는데 이 수식은 softmax function을 미분하는 과정입니다다. 이 경우 미분한 결과는 다음처럼 나오게 됩니다.

자세한 증명은 아래 유튜브 링크를 참고하시면 좋을 거 같습니다..! 저도 수학을 잘 못해서ㅠㅠ
( https://www.youtube.com/watch?v=M59JElEPgIg )
따라서 softmax를 미분해준 결과는 다음과 같이 나오게 됩니다.

우항의 첫 번째 term은 k=1일때, 두 번째 term은 k≠1 일때를 의미하게 됩니다.
해당 수식을 전개하면 아래와 같이 나옵니다.

여기서 맨 우측 하단 항을 보면 괄호 안에 있는 sigma term은 결국 모든 k에 대한 합이므로 1이 되고 따라서 다음과 같이 수식으로 전개가 됩니다.

자 이제 다음 이 부분을 미분해보겠습니다. ( 이제 겨우 한 부분 끝냈습니다..! )

Computational Graph로는 이 부분이겠네요.

여기는 다음과 같이 simple하게 수식이 전개가 됩니다.

위 수식의 경우 last time인 3-step에서의 gradient을 구했지만 만약 이전 step인 2-step에서는 어떠했을까요? 즉,

Computational Graph로는

여기서의 gradient는 어떻게 될까요? 여기서는 과거 3-step에서의 gradient의 정보도 전달이 되어야 하기 때문에 식의 구성이 조금 다르겠죠.
이 경우를 구할 때에는 2-step에서의 loss 만이 아니라 이전 3-step에서 발생한 loss도 같이 gradient가 계산이 됩니다. 즉 아래 수식을 보면,

파란 부분이 우리가 이전에 배운대로 해당 step에서의 gradient라면, 그 뿐만 아니라 이전 3-step 때의 gradient도 계산이 되고 나아가 hidden-to-hidden을 연결하는 weight의 gradient도 계산이 됩니다.
그래서 해당 수식을 전개하면 아래와 같이 나옵니다.

저기서 이제 검은 박스로 표시한 부분의 gradient를 구하면 되는데 해당 부분은

해당 수식의 미분을 거치면 되기에
tangent hyperbolic 미분 공식인

을 이용하여 해당 수식을 전개하면

우측 수식처럼 나오게 됩니다.
따라서 이렇게 구해놓은 term들을 활용하면 RNN 수식

을 구성하는 모든 파라미터들의 loss에 대한 gradient 값을 계산할 수 있게 됩니다.

조금 수식이 복잡한 부분이 있었네요.. 혹시 수식과 관련해서 오류가 있으면 언제든 코멘트 부탁드립니다..!
다음으로는 Bidrectional RNN에 대해 살펴보겠습니다.
Bidrectional RNN
우리가 이제껏 다루었던 RNN 아키텍처는 과거 정보를 바탕으로 현재의 정보를 예측하는 방법이었습니다. 하지만 실제로는 과거 많이 아니라 예측하려고 하는 term 이후의 정보도 활용하는 경우가 존재합니다.
다음 예시를 살펴보겠습니다.
- I am _.
- I am _ hungry.
- I am _ hungry, and I can eat half a pig
- 빈칸 후보군 -> ( happy, not, very )
즉 문장 마다 뒤의 정보에 따라 빈칸에 들어갈 적합한 말이 달라지기 마련입니다.
이러한 정보를 활용하기 위해, Bidirectional RNN이 등장하였습니다.
아이디어는 되게 simple합니다. 단순히 양방향에서 오는 RNN을 concatenating을 하면 되기 때문입니다.
자 다음으로는 Encoder-Decoder 구조를 살펴보겠습니다.
Encoder-Decoder
여기서의 핵심은 input sequence와 output sequence가 동일한 길이일 필요가 없는 것입니다. 대표적인 many-to-many 구조죠.
Encoder-Decoder의 아키텍처는 다음과 같이 나타낼 수 있습니다.

즉, Encoder와 Decoder는 RNN 구조로 되어 있으며 Encoder를 통과하여 마지막 layer의 hidden state를 문맥 정보를 담고 있다고 해서 'Context vector'로 명명합니다. ( 그림 상에는 C를 의미 ). 다음으로 이를 Decoder에 넣어주어 output form에 맞는 sequence를 도출합니다.
해당 구조를 사용하는 대표적인 예시가 바로 기계 번역 예시입니다.
이 Sequence to sequence에 대한 자세한 설명은 제 개인 블로그 포스팅에도 정리되어있으니 참고하시면 좋을 거 같습니다.
https://yscho.tistory.com/40?category=1040586
[논문 리뷰] Sequence to Sequence Learning with Neural Networks
강의 참고용 https://www.youtube.com/watch?v=4DzKM0vgG1Y 강의는 동빈나님의 강의를 참고하였습니다. seq2seq는 말 그대로 sequence to sequence, 즉 한 나라의 언어로 된 시퀀스를 다른 나라의 언어 시퀀스로..
yscho.tistory.com
조금 더 구체적으로 기계 번역의 예시를 들어 설명해보겠습니다.
일반적인 RNN 기계 번역을 살펴보겠습니다.

hidden state는 이전까지 입력되었던 정보를 나타냅니다. 우선 초기 hidden state인 h0는 0으로 초기화한 hidden state로 가정합니다. 이 다음 처음 토큰인 ‘나는’이라는 입력이 들어오면 ‘나는’이라는 입력 데이터 정보를 가지게 되는 h1 hidden state가 구축이 됩니다. 다음으로 이 h1을 기반으로 1차 번역이 이루어 지고 ‘I’ 이 hidden state가 다음 stage로 넘어간 다음 ‘치킨이’라는 토큰이 입력되면서 “나는 치킨이”라는 정보를 담고 있는 h2 hidden state가 구축이 됩니다. 이러한 방법을 통해 번역이 수행되게 됩니다.
하지만 현실적으로 input과 output 사이즈를 동일하게 함으로서 번역에 제한이 있고 또한
영어와 한국어의 경우 목적어와 서술어의 순서 차이도 문제가 되기 때문에 정확하게 사용되기는 어려운 한계가 존재하였습니다.
“그래서” Seq2Seq 저렇게 하나의 토큰 별 output을 도출하는 방법이 아닌 전체 시퀀스에 대한 입력 값을 받아 context vector를 만든 다음에 decoding을 해주는 방법으로 접근을 시도했다고 볼 수 있습니다.
즉, 아래 그림과 같습니다.

여기서 인코더의 경우는 마지막 hidden state를 context vector로 사용하고 ( 마지막 ht가 앞선 문맥에 대한 정보를 가지고 있기 때문이다. ) 인코더와 디코더는 다른 가중치 값을 가지게 됩니다.
하지만 분명 이 sequence to sequence 형태의 구조도 한계를 가지게 되는데, 바로 이 context vector C가 모든 정보를 다 담기에는 사이즈가 제한된다는 것입니다.
이에 대응하기 위해 나온 것이 바로 Attention이라는 방법입니다. Transformer의 기저 알고리즘으로 유명하죠.
그러면 Attention이 뭔지 잠깐 살펴보겠습니다.
Attention 관련 논문 리뷰도 제 개인 블로그에 정리되어 있으니 참고 부탁드립니다.
https://yscho.tistory.com/54?category=1040586
[논문 리뷰] Neural Machine Translation by Jointly Learning to Align and Translate
참고 강의 : jiyang Kang 님의 강의 https://www.youtube.com/watch?v=upskBSbA9cA 본 논문의 등장 배경은 기존 seq2seq의 한계점을 보완하고자 하는 모형이다. 우선 다음 그림은 이전 포스팅에서 사용한 그림이..
yscho.tistory.com
Attention을 들어가기 전에, 먼저 'Key-value' 자료구조 형태를 잠깐 짚고 넘어가겠습니다.

Key-Value에 대해 잘 설명된 문구가 있어 인용하면 다음과 같습니다.
"어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구합니다. 그리고 구해낸 이 유사도를 키와 맵핑되어있는 각각의 '값(Value)'에 반영해줍니다. 그리고 유사도가 반영된 '값(Value)'을 모두 더해서 리턴합니다. 여기서는 이를 어텐션 값(Attention Value)이라고 하겠습니다."
출처 : https://wikidocs.net/22893
1) 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 ...
wikidocs.net
저기서 해당하는 Q, K, V는 다음과 같이 맵핑이 됩니다.

그럼 본격적으로 Attention 개념을 정리해보겠습니다.
참고로 이에 대한 보충자료로 실습이 잘 정리되어 있는 블로그를 추가로 공유합니다. 공부하실 때 참고하시면 좋을 거 같습니다.
[Pytorch] 차근차근 구현하는 seq2seq + attention mechanism
날렵한 곰의 차근차근 구현하는 시리즈 입니다. * 구현 연습을 하는 단계에서 쓴 글입니다. 대충 무슨내용인지는 아는데 구현은 직접하고 싶고 할라니까 아리까리하고 할 때 보면 좋다! 논문과
luna-b.tistory.com
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 것입니다.
단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 되는 것입니다.
다양한 어텐션 케이스가 존재하는데, 이 중 dot-product attention을 살펴보겠습니다.

즉, 위의 예시를 바탕으로 정리해보겠습니다.
Attention mechanism을 이해하기 위해 5가지 스텝을 밟게 됩니다.
(1) attention score 구하기

h1, h2, h3, h4는 각 time-step 별 encoder의 hidden state 의미 (Key).
decoder의 현재 시점 t에서의 hidden state 를 st라고 정의 (Query)
자 우선 저희는 최종적으로 다음 task를 수행할 것입니다. 기존 seq2seq에서의 디코더에서 t 시점의 입력으로는 이전 시점의 출력 단어와 hidden state가 입력으로 들어오지만, 여기서는 attention value라는 값이 추가로 들어가게 됩니다. 바로 이 attention value를 구하는 과정을 살펴보도록 하겠습니다.
그 과정으로 처음 구해야 하는 것이 바로 attention score입니다.
어텐션 스코어란 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 은닉 상태 st와 얼마나 유사한지를 판단하는 스코어값을 의미합니다.
즉, 여기서 Q, K, V의 연산이 나오게 된다.
Dot product attention에서는 이를 구하기 위해, t 시점의 디코더 hidden state st와 각 encoder의 hidden state와 dot product를 수행합니다.

이를 수식으로 나타내면 다음과 같습니다.

그리고 이를 담고 있는 t시점의 디코더의 어텐션 스코어 모음값을 et라고 하면 다음과 같이 정의가 가능합니다.

(2) Softmax 함수를 이용한 Attention Distribution

자 이제 앞서 구한 attention score를 바탕으로 attention distribution을 구하는 과정을 살펴보겠습니다.
우선, 앞서 구한 et에 softmax를 적용하면 합이 1이 되는 확률 분포를 얻어낼 수 있습니다.
이를 우리는 attention distribution이라고 부릅니다. 그리고 각각의 값은 attention weight라고 부르게 됩니다.
위 그림에서는 빨간색 직사각형이 이를 의미하게 됩니다.
디코더 t 시점에서의 어텐션 가중치 값은 수식 상으로는 다음과 같이 나타낼 수 있습니다.

(3) Attention Value 구하기
자 이제 최종 관문인 attention value를 구하는 과정을 살펴보겠습니다.
앞서 구한 attention weight들을 저희는 다시 각 encoder의 hidden state와 곱하고 최종적으로 더하는 과정을 거치게 되는데 이러한 과정을 통해 값이 계산되는데 이것이 바로 attention value가 됩니다.

그리고 바로 이 attention value가 최종 context vector로서의 역할을 수행하고 이를 이제 t 시점의 디코더의 출력을 위한 입력으로 넣어주어야 합니다.
(4) Attention value와 t 시점의 디코더 hidden state와 concatenate

다시 앞서 언급했듯 t시점의 디코더에서 입력으로는 이전 시점의 출력 단어와 hidden state와 더불어 어텐션 value 가 들어가게 됩니다.
이 때 이를 넣는 방법은 t 시점의 은닉 상태에 concatenate을 시키게 됩니다. concatenate한 결과는 위 그림에서 vt를 의미합니다. 그리고 바로 이 vt를 y_hat을 예측하는 데 활용하게 됩니다.
(5) 출력층 연산의 입력 st_tilda를 구함

이 vt를 바탕으로 가중치 행렬 Wc와 곱하고 나서 tanh를 통과시켜 구한 st_tilda를 계산합니다.
즉, 기존에 출력층의 입력이 st가 아닌 어텐션 메커니즘에서는 st_tilda가 되는 것이죠.

그리고 마지막으로 이 어텐션 value를 활용한 st_tilda를 가지고 예측 값을 도출하는 식으로 구성이 됩니다.

이렇게 Attention을 통해서 기존 seq2seq의 한계점을 극복하고자 하였습니다.
자 그렇다면 과연 저 문제만 있을까요?
기본적으로 컴퓨팅 연산 속도와 데이터가 방대해지면서 더 많은 파라미터들을 학습할 필요가 있었고 뉴럴넷의 깊이는 더욱 깊어지면서, RNN에서도 그러한 연구가 많이 이루어졌는데
RNN는 특히 다음과 같은 gradient 문제에 더더욱 취약한 모습을 보였습니다.
- Exploding gradient
- Vanishing gradient
위 같은 문제가 발생한 이유가 무엇일까요? RNN의 구조를 다시 훝어보면

다음과 같은 형태가 됩니다. 즉, stage 별 weight를 계속해서 곱해지는 형태가 되는 것이죠.
한 마디로 저 W가 계속 곱해지는 겁니다.
그렇다면 저 W를 한번 뜯어봅시다.
W에 대해 고유값 분해를 해보면 아래와 같이 나오게 됩니다.
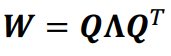

결국 저 h_t는 다음과 같이 나오게 됩니다.
맨 맽의 수식에서 eigenvalue를 보면, t 승이 자꾸 곱해지는 경향이 있는데
-> 이는 곧 eigenvalue < 1 이면 decay to 0, eigenvalue > 1 이면 explode 하게 됨을 의미합니다.
이런 문제는 vanishing gradient and exploding gradient 을 낳을 수 있습니다.
위 두 문제 중 Exploding gradient는 상대적으로 탐지하기 쉽게 일반적인 대응 방법이 존재합니다. 대표적인 방법으로는 'Gradient Clipping'이 있습니다. 이에 대해서는 제 블로그 포스팅에도 게시해놓았으니 본 포스팅에는 따로 다루지는 않겠습니다.
https://yscho.tistory.com/100?category=1040585
[Deep Learning] Gradient Exploding Debugging 맨 땅에 헤딩하기
참고했던 블로그들 도움 주셔서 감사합니다..! https://sanghyu.tistory.com/87 https://eehoeskrap.tistory.com/582 https://programs.wiki/wiki/loss-is-always-nan-and-accuracy-is-always-a-fixed-number.html..
yscho.tistory.com
그렇다면, vanishing gradient는 어떻게 해결하고자 할까요?
- Truncated BPTT
- Long-short term memory (LSTM) & GRU
다음을 살펴보겠습니다.
Truncated Backpropagation Through Time
자 다음 그림을 보시죠.

위 그림처럼 깊이가 매우 깊은 뉴럴 넷에서 backpropagation을 수행하게 되면 vanishing gradient 문제가 발생할 수 있습니다.
그래서 이를 다음과 같이 truncate해서 chunck별로 backpropagation을 수행하는 아이디어가 등장하게 됩니다.

그래서



forward를 수행할 때는 점점 hidden states 정보들을 chuck가 넘어감에 따라 계속 정보를 가져갑니다.
하지만 backpropagate은 chunk 단위로 업데이트를 함으로써 vanishing gradient를 막고자 하였죠.
다음으로는 LSTM 방법을 살펴보겠습니다.
LSTM
LSTM 아키텍처에 대해서는 본 블로그의 설명이 매우 잘 정리되어 있습니다. 본 포스팅도 본 블로그를 바탕으로 정리하였습니다.
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
Long Short-Term Memory (LSTM) 이해하기
이 글은 Christopher Olah가 2015년 8월에 쓴 글을 우리 말로 번역한 것이다. Recurrent neural network의 개념을 쉽게 설명했고, 그 중 획기적인 모델인 LSTM을 이론적으로 이해할 수 있도록 좋은 그림과 함께
dgkim5360.tistory.com
일반적인 RNN 구조를 다시 Gate화 해서 그려보면 아래와 같습니다.

하지만 LSTM은 조금 더 복잡한 구조를 취하게 되는데

바로 RNN의 히든 state에 cell-state를 추가한 구조입니다. 이 cell-state를 통해 vanishing gradient를 막고자 하였죠.
그럼 한 번 디테일을 살펴보겠습니다.
우선 핵심이 되는 Cell State 부터 살펴보겠습니다.

Cell state는 컨베이어 벤트와 같아서, 작은 linear interaction만을 적용시키면서 전체 체인을 계속 구동시킨는 역할을 합니다.
이 컨베이어벨트에 뭔가를 더하게나 빼게 되는데 이는 바로 뒤이어 설명할 gate layer에 의해 제어가 됩니다.
그 제어를 구체적인 실행으로 옮기는 녀석들로 ‘sigmoid layer’와 ‘pointwise 곱셈’이 있습니다.

sigmoid layer는 0과 1사이의 숫자를 내보내는데 이 값은 각 구성 요소가 어느 정도의 정보를 전달해야 하는지를 나타내는 수치를 의미합니다. 0이면 넘기지 말고 1이면 모든 것을 넘기라는 뜻이 됩니다.
그럼 구체적으로 gate-layer들에 대해 살펴보겠습니다.

우선 h_t-1 로부터 정보를 받게 되면 cell state로부터 어떤 정보를 버릴 것인지를 전달해줍니다.
이는 sigmoid layer에 의해 결정되며 forget gate layer라고도 부른다.


다음으로 버릴 것을 정했으니 이제 cell state에 취할 녀석을 정해야겠죠. input gate layer는 sigmoid layer가 어떤 값을 업데이트할 것인지를 정하고, 그 이후 tanh layer가 cell state에 들어갈 후보값 C_tilda vector를 만들고 cell state에 더할 준비를 마칩니다.


그리고 재료 손질이 완료 되었으면 이제 과거 state인 C_(t-1) 을 업데이트해서 C_t를 만드는 작업을 거칩니다. 재료를 준비했으니 이제 실제로 f와 i를 이용해서 실제 취할 녀석과 버릴 녀석을 통해 C_t를 만들어내게 됩니다.


이제 output을 넘겨 h_t를 구하는 부분입니다. 여기서는 앞서 구한 C_t를 활용해서 cell state의 어느 부분을 output으로 보낼 지를 정합니다. 그 방법으로는 input 데이터를 sigmoid layer를 통과시켜 o_t를 구하고 그 값을 C_t에 tanh layer를 통과시킨 값을 곱해 최종적으로 output으로 우리가 보내고자 하는 부분만 h_t에 통과시키게 됩니다.
자 그렇다면 왜 이게 vanishing gradient에 강건한 것일까요? 바로 'Cell state'가 backpropagation이 이루어지는 부분이기 때문입니다.

즉 기존의 W를 계속해서 곱해가는 형식이 아닌 C_t에서 C_(t-1)으로 역전파를 수행함으로서 f의 elementwise multiplication이 수행되기 때문에 gradient가 소실되는 것을 방지할 수 있게 됩니다.
따라서 앞서 구한 LSTM 모형을 요약하면 아래 그림과 수식으로 나타낼 수 있을 것 같습니다.

이상 Sequence Modeling에 대한 포스팅이었습니다! 긴 글 읽어주셔서 감사합니다!
Reference,
[1] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
Chapter 8, Optimization for Training Deep Model
[2] https://wikidocs.net/22893
[3] https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
[4] https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
[5] https://jimmy-ai.tistory.com/262
[6] https://wikidocs.net/22886
[7] https://casa-de-feel.tistory.com/39
[8] http://www.ktword.co.kr/test/view/view.php?m_temp1=4093
[9] https://americanoisice.tistory.com/54
[10] https://hwiyong.tistory.com/327
[11] https://ratsgo.github.io/deep%20learning/2017/04/03/recursive/
'ML & DL & RL' 카테고리의 다른 글
| [Deep-Learning] 나만의 CNN 구현해보기 실습 (1) | 2022.09.30 |
|---|---|
| [Deep-Learning] 2D Convolution operation (2) | 2022.09.24 |
| [ Computer Vision ] Object Detection - RetinaNet & EfficientDet (2) | 2022.07.09 |
| [ Computer Vision ] Object Detection - SSD & YOLO (0) | 2022.07.02 |
| [ Computer Vision ] Object Detection - RCNN, Fast RCNN, Faster RCNN (0) | 2022.06.23 |



