
No Limitation
[Deep-Learning] 나만의 CNN 구현해보기 실습 본문
본 포스팅은 카이스트 주재걸 교수님의 '컴퓨터 비전을 위한 심층학습' 수업의 과제 일부를 수행한 결과를 포스팅으로 정리한 것입니다.
익숙한 convolution 연산에 대해 조금 더 심층적으로 들어가기 위해 MNIST 데이터셋으로 먼저 간단한 네트워크를 구축을 시도하였습니다. 정확도는 97% 이상이 나오는 것을 타겟으로 네트워크 디자인을 시도하였습니다.
대부분의 CNN 계열의 네트워크들은 대개 다음과 같은 논리를 많이 사용합니다.
Convolution -> Batch Normalization -> ReLU activation -> Max Pooling
다음 순서로 디자인이 되는 경우고 각각의 instance는 매우 중요한 역할을 수행합니다.
Convolution
우선 convolution 연산은 이미지를 feature화 하는데 가장 중요한 특징을 가지게 됩니다. 구체적으로는 이미지를 잘 분석할 수 밖에 없는 'inductive bias'를 가지게 되는데요, 대표적으로 ‘translation equivariance’와 ‘locality’를 들 수 있습니다. 특별히 locality가 중요한데, fully connected layer는 입력의 모든 픽셀별로 다 연산을 수행하면서 입력을 flatten하게 전환하여 다음 layer로 넘기는 반면, convolution 연산은 그러한 이미지의 구조를 그대로 유지한 채 filter를 통한 국지적인 정보를 하나씩 넘기게 됩니다. 따라서 이미지의 edge나 texture 같은 정보들을 더욱 잘 뽑아낼 수 있는 장점이 존재하면서 동시에 모든 input을 전부 고려하면서 입력이 들어가지 않기 때문에 연산의 수가 더 적게 됩니다. 그래서 현재까지도 CNN은 이미지 분야에서 SOTA를 이루고 있죠.
Batch Normalization
또한 딥러닝을 구축하는 데 핵심 아키텍처가 되고 있는 배치 정규화 ( Batch Normalization ) 입니다. 이는 레이어가 깊어질 수록 layer별로 데이터들이 형성하는 distribution이 낮음으로 말미암아 발생하는 문제 ( internal covariate shift ) 를 극복하고자 도입된 방법으로 학습 속도도 높여주며, 가중치 초기화에 대한 의존도를 낮춤으로서 훨씬 efficient하게 네트워크를 강화시킵니다. 사실상 현대에서는 BN는 거의 필수 아키텍처가 되고 있죠.
ReLU activation
또한 모형의 비선형성을 도입하기 위한 activation function 중 가장 압도적인 사용량을 보이고 있는 ReLU가 CNN에서도 많이 사용이 되고 있습니다.
Max Pooling
마지막으로는 Pooling 연산인데요. 사실 pooling에는 max만이 아닌 average-pooling 등 다양한 연산이 존재하지만 현대에 들어서는 대부분 max-pooling을 수행하게 됩니다. pooling은 연산의 수를 줄여주는 것에 가장 큰 공헌을 하며, 이미지의 특징을 뽑아내는 데에 크게 성능을 헤치지 않으면서 대표값을 훨씬 효율적으로 뽑아줄 수 있는 구성요소입니다.
그렇다면 이제 이들을 활용해서 직접 CNN 네트워크를 구축해보겠습니다.
우선, MNIST 데이터를 불러오는 과정을 거치겠습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.datasets as vision_dsets
import torchvision.transforms as T
import torch.optim as optim
from torch.autograd import Variable
from torch.utils import data
## 이 코드 외에 MNIST_Data는 불러오는 코드가 많으니 다른 코드를 참고하셔도 됩니다.
def MNIST_DATA(root='./',train =True,transforms=None ,download =True,batch_size = 32,num_worker = 1):
mnist_train = vision_dsets.MNIST(root = root,
train = True,
transform = T.ToTensor(),
download=download)
mnist_test = vision_dsets.MNIST(root = root,
train = False,
transform = T.ToTensor(),
download=download)
trainDataLoader = data.DataLoader(dataset = mnist_train,
batch_size = batch_size,
shuffle =True,
num_workers = 1)
testDataLoader = data.DataLoader(dataset = mnist_test,
batch_size = batch_size,
shuffle = False,
num_workers = 1)
return mnist_train,mnist_test,trainDataLoader,testDataLoader
trainDset,testDset,trainDataLoader,testDataLoader= MNIST_DATA(batch_size = 32, download = True)MNIST는 흑백이므로 채널은 1이고 28x28의 이미지로 입력받게 되고 클래스는 0~9로 총 10개의 class가 존재하는 형태입니다.
이제 여기서 10개의 class에 대한 예측을 수행해야 하기 때문에,
앞서 언급한 convolution + batch normalization + relu + max-pooling을 활용해서 아키텍처를 구성해보겠습니다.
batch_size=16으로 가정하겠습니다.
우선 다음과 같은 입력을 생각해보겠습니다.

이 경우 (1x28x28)의 digit 이미지가 총 16개가 있는 batch로 보시면 됩니다. ( 이미지는 마치 한 장의 이미지가 있는 것처럼 보이지만 그림은 양해 부탁드립니다.. ㅎㅎ ). 이제 여기서 다음과 같이 먼저 convolution 연산을 수행한다고 해봅시다.
우선 저 부분에 해당하는 데이터를 trainDataLoader에서 빼내어 확인해보면,
image, label = next(iter(trainDataLoader))
image.shape # torch.Size([16, 1, 28, 28])
label.shape # torch.Size([16])다음과 같이 하나의 배치를 뽑아낼 수 있습니다. 이를 'image'라고 하겠습니다.
자 다음으로 convolution 연산을 수행해보겠습니다.
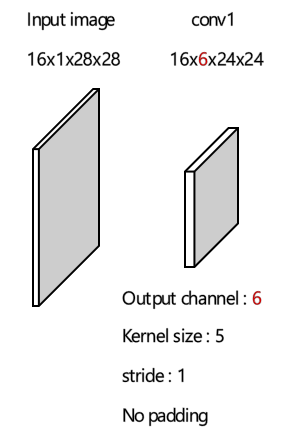
1번의 convolution 연산이 수행되었습니다. output으로 나올 채널의 수는 6으로 설정하였습니다. 그리고 filter 사이즈로는 5를 설정하였으며 stride는 1, padding은 사용하지 않았습니다. 그래서 결과적으로 output size는 24x24가 구성됩니다. 혹시 이 부분에 대해 아직 개념이 부족하신 분들은 이전 포스팅을 참고바랍니다.
[Deep-Learning] 2D Convolution operation
많이 사용하는 convolution 연산이지만 조금 더 개념적으로 다루어보고자 블로그 글을 정리합니다. Justin Johnson 교수님의 미시건 강의 'Deep Learning for computer vision Lecture 7'을 참고하였고 JINSOL KIM..
yscho.tistory.com
저 부분의 연산은 다음 코드로 수행이 가능합니다. 함수는 nn.Conv2d라는 함수를 사용합니다.
conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)
x = conv1(image)
x.shape # torch.Size([16, 6, 24, 24])
이 다음으로 순서에 의해 batch normalization을 수행해줍니다.

Batch Normalization은 size에는 따로 영향을 미치지 않습니다.
이를 코드로 구현하면 다음과 같습니다. 함수는 nn.BatchNorm2d라는 함수를 사용합니다. 이미지 형식이기 때문에 2d를 썼고 FC layer를 통과하는 flatten feature의 경우 nn.BatchNorm1d를 사용합니다.
bn1 = nn.BatchNorm2d(6) # 현재 입력 사이즈
x = bn1(x)
x.shape # torch.Size([16, 6, 24, 24])다음으로는 ReLU 활성화 함수를 통과시키는 레이어가 등장합니다.

코드는 다음과 같이 구성됩니다. 함수는 torch.nn.functional에 내장되어 있는 relu()를 사용하였습니다.
x = F.relu(x)
x.shape # torch.Size([16, 6, 24, 24])
마지막으로 pooling 단계가 남았습니다. stride는 2로 설정하였습니다.

이 경우 다른 변화 없이 Height와 Width만 반절의 크기가 됩니다.
코드 구현은 다음과 같습니다. 함수는 torch.nn.functional에 내장되어 있는 max_pool2d()를 사용하였습니다.
x = F.max_pool2d(x,2)
x.shape # torch.Size([16, 6, 12, 12])
이제 이 과정을 feature map이 16x120x1x1가 될 때까지 반복해줍니다. line by line 코드로 구성하면 다음과 같습니다.
image, label = next(iter(trainDataLoader))
image.shape
conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)
x = conv1(image) # torch.Size([16, 6, 24, 24])
bn1 = nn.BatchNorm2d(6)
x = bn1(x)
x = F.relu(x)
x = F.max_pool2d(x,2) # torch.Size([16, 6, 12, 12])
conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
x = conv2(x) # torch.Size([16, 16, 8, 8])
bn2 = nn.BatchNorm2d(16)
x = bn2(x)
x = F.relu(x)
x = F.max_pool2d(x,2) # torch.Size([16, 16, 4, 4])
conv3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=2, stride=1) # filter size = 2
x = conv3(x) # torch.Size([16, 120, 3, 3])
bn3 = nn.BatchNorm2d(120)
x = bn3(x)
x = F.relu(x)
x = F.max_pool2d(x,2) # torch.Size([16, 120, 1, 1])이제 이렇게 구성된 녀석을 마지막으로 2개의 fully connected layer를 거쳐서 10개의 최종 예측 결과를 도출하는 과정으로 구성해보겠습니다. 첫 번째는 84 dimension으로 바꾸는 연산, 두 번째는 10 dimension으로 바꾸는 연산을 수행하겠습니다.
그림으로 표현하면 다음과 같습니다.

우선 먼저 FC layer를 통과하기 위한 Flatten vector로 만들어주어야 하기 때문에 다음과 같은 연산을 수행합니다.
x = x.view(-1,120)
x.shape # torch.Size([16, 120]) -> to make flatten vectorflatten한 형태로 변환을 한 다음 다음과 같이 fully connected 연산을 수행합니다. 이는 nn.Linear()를 통해 수행 가능합니다.
fc1 = nn.Linear(in_features=120, out_features=84)
x = fc1(x)
x.shape # torch.Size([16, 84])여기서 마지막으로 10개의 class에 대한 정보를 반환하기 위해 한번 더 행렬 연산을 수행합니다.
fc2 = nn.Linear(in_features=84, out_features=10)
x = fc2(x)
x.shape # torch.Size([16, 10])그리고 마지막으로 softmax layer를 통과해 최종 예측 probability를 도출하고 cross entropy loss를 통해 업데이트를 해나갑니다.
predict_result = F.softmax(x,dim=1)
자 그렇다면 이제 이렇게 line by line으로 구성한 네트워크를 class로 명확하게 정의하면 다음과 같습니다.
# TODO
class MyCNN(nn.Module):
def __init__(self):
super(MNIST_Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)
self.bn1 = nn.BatchNorm2d(6)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.bn2 = nn.BatchNorm2d(16)
self.conv3 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=2, stride=1)
self.bn3 = nn.BatchNorm2d(120)
self.fc1 = nn.Linear(in_features=120, out_features=84)
self.bn4 = nn.BatchNorm1d(84)
self.fc2 = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.bn1(self.conv1(x))
x = F.max_pool2d(F.relu(x),2)
x = self.bn2(self.conv2(x))
x = F.max_pool2d(F.relu(x),2)
x = self.bn3(self.conv3(x))
x = F.max_pool2d(F.relu(x),2)
x = x.view(-1,120)
x = self.bn4(self.fc1(x))
x = self.fc2(x)
return F.softmax(x,dim=1)
그리고 학습을 수행해보겠습니다
mnist_net = MyCNN().cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(mnist_net.parameters(), lr=0.001)mnist_net.train()
epoch=10
for e in range(epoch):
running_loss = 0.0
for i, data in enumerate(trainDataLoader, 0):
inputs, labels = data
inputs = inputs.cuda()
labels = labels.cuda()
optimizer.zero_grad()
outputs = mnist_net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if (i+1) % 500 == 0:
print('[%d, %5d] loss: %.3f' % (e + 1, i + 1, running_loss / 500))
running_loss = 0.0예측을 수행해보면 다음과 같습니다.
mnist_net.eval()
test_loss = 0
correct = 0
for inputs, labels in testDataLoader:
inputs = inputs.cuda()
labels = labels.cuda()
output = mnist_net(inputs)
pred = output.max(1, keepdim=True)[1] # get the index of the max
correct += pred.eq(labels.view_as(pred)).sum().item()
test_loss /= len(testDataLoader.dataset)
print('\nTest set: Accuracy: {}/{} ({:.0f}%)\n'.
format(correct, len(testDataLoader.dataset),
100.* correct / len(testDataLoader.dataset)))Test set: Accuracy: 9829/10000 (98%)
이상 직접 나만의 CNN 구현해보기 실습이었습니다! 긴 글 읽어주셔서 감사합니다!
참고 포스팅
https://deep-learning-study.tistory.com/503
[논문 구현] PyTorch로 LeNet-5(1998) 구현하기
안녕하세요! 공부 목적으로 LeNet-5를 파이토치로 구현해보도록 하겠습니다! 논문 리뷰는 여기에서 확인하실 수 있습니다. [논문 리뷰] LeNet-5 (1998), 파이토치로 구현하기 가장 기본적인 CNN 구
deep-learning-study.tistory.com
https://discuss.pytorch.org/t/example-on-how-to-use-batch-norm/216
Example on how to use batch-norm?
TLDR: What exact size should I give the batch_norm layer here if I want to apply it to a CNN? output? In what format? I have a two-fold question: So far I have only this link here, that shows how to use batch-norm. My first question is, is this the proper
discuss.pytorch.org
'ML & DL & RL' 카테고리의 다른 글
| Gaussian Mixture Model 개인 공부용 (0) | 2025.02.16 |
|---|---|
| [Deep Learning] Activation function & Weight Initialization & Regularization (0) | 2022.10.18 |
| [Deep-Learning] 2D Convolution operation (2) | 2022.09.24 |
| [Deep learning] Sequence Modeling (0) | 2022.09.22 |
| [ Computer Vision ] Object Detection - RetinaNet & EfficientDet (2) | 2022.07.09 |



