
No Limitation
[Deep Learning] Activation function & Weight Initialization & Regularization 본문
[Deep Learning] Activation function & Weight Initialization & Regularization
yesungcho 2022. 10. 18. 21:42본 포스팅은 미시건 EECS 498-007 Deep learning for Computer Vision 강의를 참고하여 작성되었습니다.
https://www.youtube.com/watch?v=lGbQlr1Ts7w&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=10
딥러닝을 이용하여 학습을 수행하기 전에 조치를 해줘야 하는 요소들이 존재합니다. 대표적인 것으로는
- 활성화 함수
- 가중치 초기화
- 규제화
세 가지를 들 수 있습니다. 최근 딥러닝 모형을 사용한다고 하면 반드시 사용되는 기술들이기 때문에 개념에 대한 명확한 정의가 필요합니다.
물론 요새는 활성화함수로는 거의 ReLU를 사용하고 가중치 초기화도 Xavier나 He 초기화를 사용하는 것이 국룰(?)이 됬지만 그럼에도 그 개념이 등장한 이유나 구체적으로 어떠한 기능을 수행하는 지를 알지 못하면 안되겠죠. 이미 익숙한 개념들이지만, 복습 차원에서 포스팅을 정리하게 되었고 처음 접하는 분들께도 도움이 되기를 바랍니다.
Activation Function
딥러닝의 '비선형성'을 부여해주는 대표적인 역할을 하는 것이 바로 활성화 함수입니다. 일반적인 linear regression이 분류 task를 수행할 수 있게 고안된 것이 바로 sigmoid 함수인데 이 역시 마찬가지로 활성화 함수의 기능을 수행하게 됩니다. 대표적으로는 아래 그림과 같은 종류들이 존재합니다.
본 포스팅에서는 Sigmoid, Tanh, ReLU, Leaky ReLU 정도로 살펴볼 예정입니다.

첫 번째로는 sigmoid 함수가 있습니다.

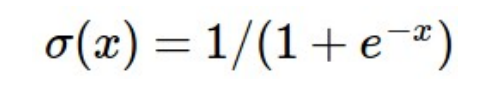
이 sigmoid의 경우는 logistic regression 이래로 가장 오래된 활성화 함수로 그 의의가 있습니다. 하지만 딥러닝이 발전한 요근래는 사용될 일이 거의 없습니다. 바로 sigmoid가 갖는 한계점 때문인데요. 바로 다음과 같은 3가지 한계점을 갖습니다.
[1] Saturated neurons 'kill' the gradient
신경망이 깊어질수록 graident가 소실, 즉, vanishing gradient가 발생합니다.
[2] Not zero-centered
[3] Exponential is compute expensive
exponential 연산이 실제로 비싸기 때문에 권장되지 않는다고 합니다.
사실 [1]의 이유는 어느 정도 backpropagation을 공부하신 분들이라면 익숙한 개념이실 겁니다.

바로 backpropagation이 수행되면서 local gradient에 곱해지는 gradient 값이 1보다 작은 값들이 계속 곱해지면서 점차 신경망이 깊어질수록 그 정보가 손실되는 문제가 발생하게 됩니다. sigmoid의 경우 미분의 경우 sig(1-sig) 형태가 되기 때문에 1보다 작은 값이 지속적으로 곱해지고 그럼으로 vanishing gradient에서 자유롭지 못한 문제가 발생합니다.
[2]의 경우는 어떠한 개념인지 살펴보겠습니다.

위 수식에서 f를 어떠한 활성화 함수라고 했을 때 매번 layer 마다 입력되는 값을 xi라고 가정하겠습니다. 저기서 만약 zero-center가 안된다면, 즉, 예를 들어 xi가 항상 positive거나 negative 값이 들어온다고 해보겠습니다. ( sigmoid의 그래프를 보면 늘 0보다 큰 값을 도출하는 것을 알 수 있습니다. 이 경우는 positive가 됩니다. )
그러면 wi와 관련된 모든 loss의 gradient는 전부 동일한 sign, 즉 xi가 모두 positive면 gradient도 positive, xi가 negative면 모든 gradient도 negative가 됩니다.
그러면 gradient를 따라 딥러닝 네트워크가 쭉 학습을 수행하게 되면, global optimal에 도달할 확률이 적어집니다. 왜냐하면 두루두루 다양한 방향으로 다녀도 봐야하는데 늘 같은 방향만 바라보는 문제가 발생할 수 있기 때문입니다. 이 경우 차원이 큰 데이터를 사용하는 경우는 더 문제가 심각해지게 됩니다. 그래서 활성화 함수는 zero-centered된 녀석을 사용하는 것이 더 바람직합니다.
하지만 이 경우는 single case에 해당하며 보통 mini batch 단위로 학습이 수행되기 때문에 적절한 배치 사이즈를 준다면 어느 정도 이 문제는 해결이 되는 것으로 알려져 있습니다.
그 다음으로 tanh, 하이퍼볼릭 탄젠트 함수에 대해 살펴보겠습니다.
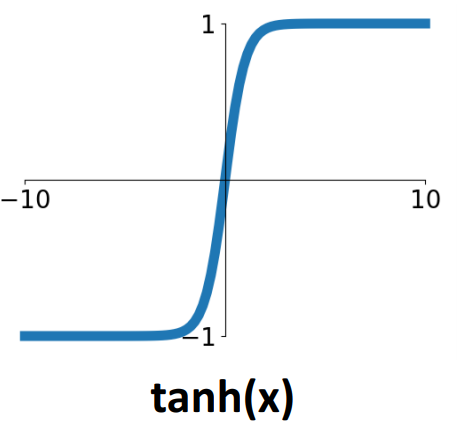
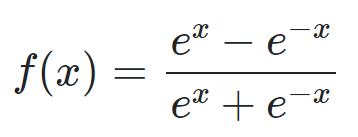
이 경우는 그림에서 알 수 있듯, zero-centered 입니다. sigmoid의 단점을 어느 정도 보완할 수 있죠. 하지만, 이 tanh 역시 vanishing gradient 문제에서 자유로울 순 없었습니다.
이 다음으로 등장한 것이 현대 가장 많이 사용되는 활성화 함수, ReLU ( Rectified Linear Unit )입니다.

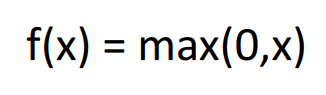
이 ReLU의 경우 입력이 음수면 0, 양수면 그 값 그대로 가져가는 특징을 갖는데, 이 경우, 비선형성이 보장이 되면서 본 값을 유지하기 때문에 vanishing gradient에도 노출될 우려가 적습니다. 또한 exponential 같은 연산에 의존하지 않기 때문에 연산도 매우 효율적이고 실제로 매우 잘 동작하는 것으로 알려져 있습니다. 현대 가장 mainstream인 activation function이기도 하죠.
하지만 이 ReLU가 갖는 한계점이 있습니다. 첫 번째로는 앞서 언급한 zero-centered 문제입니다. 이 역시 모든 input이 0 이상인 값이 들어가기 때문에 이 문제에서는 자유롭지 않습니다. 하지만 앞서 언급드렸듯 배치 사이즈를 조절하면 되기 때문에 그다지 큰 문제가 되지는 않습니다.
이보다 조금 더 sensitive한 문제가 있는데요. 이는 바로 'dead ReLU'라는 문제입니다.
위, ReLU의 수식에서 만일 입력 x가 음수인 값이 나오면 전부 0으로 바꾸어버리는 경향이 있습니다. 이 경우 만일 음수인 입력이 들어오게 되면 그 gradient 값은 0으로 인해 모두 손실되버리는 문제가 발생합니다. 즉, 그 경우는 절대 update가 되지 않는 문제가 발생하는 것이죠. 이를 dead ReLU라고 부릅니다.
그래서 이를 보완하고자 등장한 것이 바로 Leaky ReLU입니다.

즉, 조금 heuristic을 사용한 건데요. 음수 부분의 기울기를 약소하게 살려 gradient가 0이 되는 것을 막고자 하였습니다. 즉 ReLU 이후 나온 대부분의 activation function은 바로 이 ReLU를 조금 더 보완한 다양한 파생 함수들이 등장을 하게 됩니다. ( ELU, SELU, GELU, ... ).
그럼 대체 뭘 쓰냐? 이 질문에 Justin Johnson 교수님은 그냥 심플하게 결론을 내립니다. Just use ReLU. 즉 ReLU 쓰면 됩니다. 복잡하게 생각하지 맙시다.

Weight Initialization
딥러닝 학습 시 초반 가중치의 선정은 생각보다 매우 중요하게 됩니다. global optima를 찾기 위한 시작점을 setting하는 것과도 같기 때문입니다. 이 경우, 만일 극단적으로 가중치와 bias를 0으로 설정한다고 한다면, 당연히 학습은 제대로 이루어지지 않겠죠. 즉, 어떤 값이 들어오는 지에 따라 학습에는 큰 영향을 미치게 됩니다.
그러면 simple하게 랜덤한 값을 chosen한다고 생각해봅시다. 이 경우는 일부 네트워크에는 문제가 없을 수 있으나 신경망이 깊어질수록 문제가 발생한다고 합니다.
왜 그럴까요?
예를 들면 아래 코드를 살펴보겠습니다.
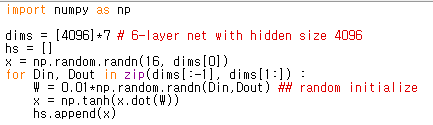
아래 코드는 Justin Johnson 교수님의 강의 자료 코드를 참고하였고 예를들면 위와 같이 6-layer로 되어 있는 신경망을 가정하게 되면 가중치 W를 랜덤하게 초기화해서 network를 디자인했다고 했을 때, 각 hidden state에 들어오는 입력들의 분포는 다음과 같이 나온다고 합니다.

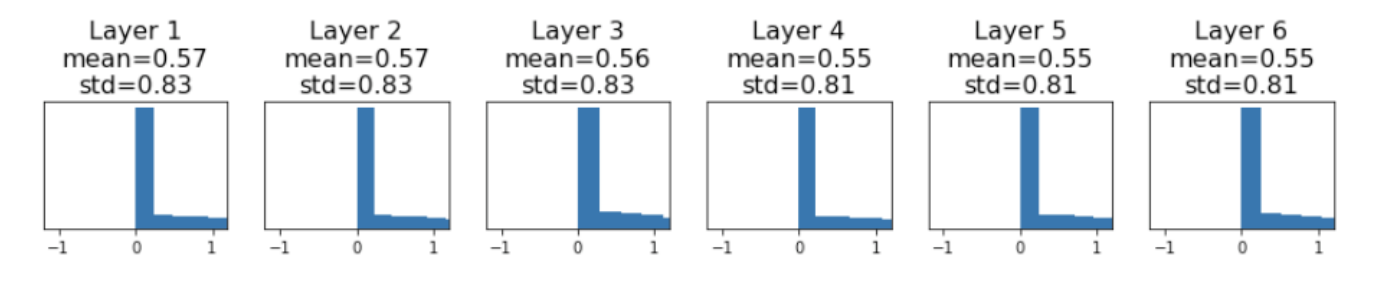
깊어지면 깊어질수록 모든 activation 이 0으로 모여드는 것을 알 수 있습니다. 즉, distribution이 layer를 지날 때마다 상이한 문제가 발생하게 되는 거죠. ( 이 문제를 internal covariate shift라고도 합니다.)
그러면 이 문제를 어떻게 해결할 수 있을까요? 물론 현대에 가장 많이 사용되는 batch normalization 역시 이 문제를 대응할 수 있지만, 가중치 초기화를 통해도 이 문제를 풀고자 하는 시도가 이전에 이루어져 왔습니다. 바로 Xavier 초기화라는 방법이 등장하게 됩니다.
이 방법은 어떻게 문제를 대응하는 지를 살펴보겠습니다.

예를 들어, 다음과 같이 입력 x와 가중치 w로 y라는 output을 도출한다고 해보겠습니다.
이 경우, x와 y의 분산이 같으면 좋겠죠. 그래서 양변의 분산을 구해보면 아래와 같이 전개됩니다.

즉, Var(yi)와 Var(xi)가 동일할 조건은 Var(wi) = 1/Din 이 되는 경우 xi와 yi의 분산이 같아지게 됩니다.
분산은 제곱 처리가 된 거니 다시 원래 단위에 맞게 곱해지는 것은 실제로 1/sqrt(Din) 이 되겠죠.
바로 이 개념을 가지고 초기화를 수행한 것이 Xavier initialization입니다. 위 코드에서 다시 적용해보면 다음과 같습니다.

그리고 이를 가지고 layer 별 분산을 구해보면 다음과 같이 나온다고 합니다.

어느 정도 layer 별로 distribution이 0에 수렴되지 않는 것을 확인할 수 있습니다.
이 Xavier initialization의 경우 활성화 함수의 입력이 zero-centered를 가정합니다. 즉, 그 말은 ReLU 같은 zero-centered가 아닌 경우는 Xavier initialization를 사용해도 학습이 잘 이루어지지 않는다는 것을 의미하기도 합니다.


이 경우를 대응해주기 위해 고안된 것이 바로 He initialization 입니다.
이는 simple하게 Xavier 방법에서 분자에 2를 더 곱해주는 형식입니다. 즉, ReLU로 인해 0이 되는 부분으로 활성화되는 영역이 적게 되는데, 이를 더 넓게 분포시키기 위해 2를 곱해주게 됩니다.

Regularization
Data Augmentation / Mixup / Cutout / CutMix ... ( 정리 중 )
Image를 다루는 vision task에서는 반드시 수행되는 절차가 Data augmentation입니다. 왜냐하면 동일한 이미지에 있어서도 보는 관점, 각도, 명도 등에 따라 사람은 같은 이미지라고 인식을 하지만 머신은 이를 다른 이미지로 인식할 수 있는 우려가 있기 때문입니다.

예를 들어 위 그림의 경우 왼쪽의 경우도 나비, 오른쪽의 경우도 나비라고 사람은 인식할 수 있지만, 머신의 경우 왼쪽의 나비만 학습한 상태에서는 오른쪽을 나비로 인식하지 못하는 문제도 존재합니다. 따라서 이를 다양한 변화를 주고 이 역시 나비로 인식하게끔 모형을 학습시키면 이러한 문제에 대응할 수 있습니다. 이것이 바로 data augmentation의 개념입니다.
위 그림에 나와있는 것처럼 많은 방법들이 존재하지만, 그 중 대표적으로 아래 카테고리를 정리하고자 합니다.
- Random crops and scales
- Mixup
- Cutout
- CutMix
random crop, scale은 가장 대표적으로 많이 사용되는 augmentation 방법입니다. 아래 블로그는 Albumentations 라이브러리를 사용하여 다양한 augmentation을 수행한 사례들을 공유하는데요, 참고하시면 좋을 거 같습니다.
https://lcyking.tistory.com/80
[딥러닝] Albumentations의 데이터 증강 이해
Albumentations의 데이터 증강 albumentations는 이미지 데이터 증강 라이브러리입니다. 이미지를 좌, 우, 회전, 색변환, 노이즈 등등 넣어서 다양한 데이터를 모델이 학습시킬 수 있게 변환해주는 것입
lcyking.tistory.com
crop의 경우 아래 그림을 예시로 들 수 있습니다.

왼쪽은 누가 봐도 강아지입니다. 하지만 crop한 사진들 역시 강아지인건 확실하기 때문에 저런 데이터를 추가로 학습시키게 모형에 넣어주게 됩니다.

Scale 역시 마찬가지입니다.
다음으로 mixup을 살펴보겠습니다.


Mixup은 말 그대로 서로 다른 클래스의 랜덤 pair에 대해 weight combination을 통해 혼합된 데이터를 generate해서 학습에 사용하는 방법입니다. 이를 통해 학습의 안정성을 꾀하는 방법입니다.

Cutout은 어떨까요? 이렇게 중간 중간 고양이의 부분을 cutout해버리게 되더라도 사람은 충분히 저 그림이 고양이라는 것을 인식할 수 있으므로 이를 통해 모형을 더 robustness하게 만들 수 있는 전략입니다. 그리고 이 방법은 object occlusion이라는 문제를 해결하고자 등장한 방법이기도 합니다.
Object occlusion은 다음과 같이 실제 vision task에 많이 발생하는 이슈인데 detecting할 object가 다른 물체에 의해 가려지거나 하는 이슈를 의미합니다. 쉽게 아래 그림과 같습니다.

저 기둥 뒤에 있더라도 사람이라는 것을 사람은 알 수 있기에 저 부분을 머신이 쉽게 예측할 수 있게끔 도와주는 것으로 Cutout 아이디어가 등장하게 됩니다.

CutMix는 기존 Cutout이 0으로 넣어버리는 부분에 있어 정보 손실, Mixup에서 발생하는 기존 이미지의 왜곡을 방지하기 위해 다른 class의 이미지를 집어 넣음으로서 기존 한계를 개선하고 image classification 뿐만 아니라 localization ability를 키움으로서 더 robust한 모형을 만들 수 있었다고 언급합니다. 이 방법 또한 다양한 augmentation 기법으로 많이 활용됩니다.
이상 기본적인 activation function, weight initialization, data augmentation 기법에 대해 정리해보았습니다.
긴 글 읽어주셔서 감사합니다.
'ML & DL & RL' 카테고리의 다른 글
| 분포 거리에 대한 개념적 고찰 (KL Divergence, JS Divergence, Wasserstein Distance) (0) | 2025.04.29 |
|---|---|
| Gaussian Mixture Model 개인 공부용 (0) | 2025.02.16 |
| [Deep-Learning] 나만의 CNN 구현해보기 실습 (1) | 2022.09.30 |
| [Deep-Learning] 2D Convolution operation (2) | 2022.09.24 |
| [Deep learning] Sequence Modeling (0) | 2022.09.22 |



