
No Limitation
[ Computer Vision ] Object Detection - SSD & YOLO 본문
본 포스팅은 개인 학습용으로 작성되었고 권철민 님의 '딥러닝 컴퓨터 비전 완벽 가이드' 강의 내용을 참고하였습니다.
이번 포스팅에서는 Object Detection task에서 One-stage Detector의 대명사인 YOLO - v1,v2,v3와 SSD에 대해 공부해보겠습니다.

앞서 배운 RCNN 계열의 모형들은 모두 ‘Two-stage Detector’로서 Region proposal을 별도의 stage로 나누어 동작하는 방법입니다. 하지만 실시간 요구 사항을 만족시킨 어렵다는 한계점이 존재합니다. 속도가 그렇게 빠르지 않기 때문이죠. 자율 주행같은 real world문제를 풀기 위해서는 정확도 만큼이나 inference의 속도가 중요한데 가장 SOTA에 위치하는 Faster RCNN의 경우도 사실상 수행 속도가 7fps 정도밖에 되지 않기 때문에 그다지 빠른 수행 성능을 보이지 않습니다.
그래서 이 Region proposal 단계를 나누지 않고 one-stage로 진행을 하게 되는 방법도 주목을 받게 되었는데요, 시초인 YOLO-v1 부터 시작해서 SSD, Retina-Net과 EfficientDet 같은 여러 알고리즘이 나오면서 더 발전을 하게 되었습니다.
처음에는 One-stage Detector의 시초인 YOLO-v1은 Faster-RCNN보다 inference 속도는 훨씬 더 빨랐지만, 아쉽게도 detecting 성능이 그렇게 좋지 못했습니다. 이 때, one-stage 방법으로 성능과 속도를 처음으로 잡은 방법이 바로 SSD, Single Shot Detector 입니다.
자 그럼 SSD에 대해 살펴봅시다.
Single Shot Detector
Single shot detector에 대해 개괄적인 정보를 담은 figure부터 보시죠.

위 그림은 SSD 논문에서 가져온 그림인데 거시적인 구조만 그리면 다음과 같습니다. 그림을 보면 알 수 있듯, feature map이 convolution 연산을 수행하면서 각 stage 별로의 feature map 마다마다 classifier를 붙이는 것을 확인할 수 있습니다. 조금 특이한 구조인데 왜 이러한 아이디어를 사용하였는 지 확인해보겠습니다.
우선 SSD에서는 크게 2가지 구성을 기억하는 것이 중요합니다
1. Multi Scale Feature Layer
2. Default (Anchor) Box
Multi Scale feature layer가 바로 위에서 언급한 feature map의 level별로 정보를 바탕으로 detection에 활용하는 것을 의미합니다. 두 번째의 default box는 Faster RCNN에서 도입한 그 anchor box와 동일한 의미인데, 본 논문에서는 default box라는 용어를 사용합니다. anchor box에 대해서 잘 모르시는 분은 이전 포스팅의 Faster RCNN 부분을 참고해주시면 될 것 같습니다.
[ Computer Vision ] Object Detection - RCNN, Fast RCNN, Faster RCNN
본 포스팅은 개인 학습용으로 작성되었고 권철민 님의 '딥러닝 컴퓨터 비전 완벽 가이드' 강의 내용을 참고하였습니다. 금일 포스팅에서는 Object Detection task의 기본이 되는 RCNN 계열의 알고리즘
yscho.tistory.com
자 그렇다면 우선 첫째로 Multi Scale Feature Layer 개념부터 살펴보겠습니다.

마땅한 사진 쓸게 없어서 제 5년 전 증명 사진을 가져왔네요. 예를 들어 위 빨간색 사진이 window라고 하면 전통적인 window slicing 기법에서 저렇게 scale에 따라 object가 잘 detect될 수도 있고 잘 안될 수도 있다는 것을 알고 있습니다. 큰 사진에서는 저 window size로는 얼굴을 제대로 인식하지 못해 누구인지 명확하게 알 수는 없지만, 이미지를 더 줄임으로서 맨 오른쪽의 size로는 명확하게 누구인지 파악할 수 있을 정도로 정보를 얻을 수 있습니다. 이 방법을 바로 이미지 피라미드라고 합니다.

하지만 실제로 Image scale의 방법으로 수행할 때는, 이 때 window 사이즈는 고정해놓고 수행하는데 multi object를 효과적으로 detect하기도 어렵고 detect에 문제가 많게 됩니다.
그래서..! 만약에 원본 이미지가 아니라 다른 크기의 feature map을 이용한다면 정보를 유지하면서 효과적으로 detect를 수행할 수 있지 않을까? 에서 출발한 것이 바로 SSD의 아이디어입니다.

즉, feature map을 통해 점점 compact해지면서 얻는 특징들을 바탕으로 detection을 수행하는 아이디어입니다. 예를 들어 32x32 같은 큰 feature map은 8x8에 비해 비교적 작은 object들을 잘 detect할 수 있게 됩니다. 반면 8x8 같은 경우는 작은 window를 사용해도 큰 object를 잘 detect할 수 있게 되죠. 이 모든 정보를 활용하자는 아이디어에서 출발합니다.
다음으로 Default Box 개념에 대해 공부해봅시다.

기존 Faster RCNN에서는 위 그림에 보이는 Region proposal network에서 먼저 object가 있을 법한 곳을 찾고(bbox regression) detection을 수행함을 알 수 있습니다. 하지만 기존에는 저 부분과 뒷단 detection 영역을 구분지었는데 굳이 그럴 필요가 있을까요? 이를 하나로 합칠 수는 없을까요? 그리고 그 기반이 되는 것이 바로 default box 개념을 활용하는 방법입니다.
즉, Region proposal로만 default box를 사용하지 말고 그냥 object detection에 바로 활용하자는 아이디어입니다. 이렇게 바로 하니까 훨씬 속도가 빨라지게 되죠.

예를 들어 위 예시에서 feature map에서 활성화 되는 부분이 존재하게 되는데 ( 물론 위 그림은 그저 예시기 때문에 명확하지는 않습니다 ) 바로 그 부분의 defeault box를 통해 object class를 분류하고 bbox regression을 수행함으로써 정보들을 얻을 수 있습니다. 이렇게 feature map단위로 compact되진 데이터에 각각의 default box의 정보를 바탕으로 detection을 수행하는 방법으로 동작하게 됩니다.
자 그럼 위에서 살펴본 구조를 다시 뜯어보겠습니다.

우선 SSD 에서는 입력으로 들어가는 이미지는 300x300과 512x512로 고정되어 있는 것이 특징입니다. 그래서 SSD300과 SSD512로 구분해서 성능을 측정할 때 표기하게 됩니다.
다음으로 앞서 언급드렸듯 서로 다른 feature map에 classifier가 붙어있음을 알 수 있습니다. 그리고 그 classifier의 결과들이 끝의 detection하는 곳으로 모여 있음을 알 수 있습니다.
그 다음 어떻게 anchor box의 정보들을 학습을 시키는지 보면, 각 feature map 별로 3x3 convolution 연산을 수행합니다. 예를 들어 38x38x512 feature map에 classifier는 다음과 같이 구성됩니다.
Conv : 3x3x(4x(classes+4))
위에서 앞의 4는 anchor box의 수가 되고 ( 그런 경우 총 anchor box의 수는 38x38x4 ) 뒤의 (classes+4)는 개별 anchor box가 채워야 하는 정보를 의미하는데 구체적으로는 classes는 정답 label의 수가 되고 +4는 Bbox의 좌표(x,y,w,h)의 값이 됩니다.
이런 경우 끝의 detection 단에는 총 8732개의 anchor box가 만들어지게 됩니다.
물론 여기서 만든 모든 8732개의 anchor box를 다 쓰지 않고 'Non-max suppression' 방법을 이용해서 필터해서 가장 IOU가 높은 anchor box를 추려서 뽑게 됩니다.
Non-max suppression 방법은 간단하게 소개하면 다음과 같습니다.

예를 들어 저렇게 자동차를 detect하는 bbox의 후보군이 왼쪽처럼 나왔다면 이를 잘 대표하는 것은 당연히 오른쪽의 bbox일 것입니다. 문제는 이 bbox를 어떻게 추릴 것인가하는 문제입니다. 바로 다음과 같은 step을 밟게 됩니다.
개별 class별 NMS 수행!
[1] 특정 confidence 값 이하는 모두 제거
[2] 가장 높은 confidence 값을 가진 순으로 bbox 정렬
[3] 가장 높은 confidence 값을 가진 bbox와 IOU와 겹치는 부분이 IOU threshold보다 큰 bbox는 모두 제거
[4] 남아 있는 bbox에 대해 3번 step을 반복
이렇게 object별로 가장 명확한 bbox를 뽑게 됩니다.
자 그럼 위의 38x38x512 feature map에 3x3 conv 연산에는, 특히 4개의 anchor box에는 어떠한 정보를 바탕으로 연산이 되는 지를 살펴보겠습니다.

예를 들어 저렇게 38x38x512의 feature map이 있다면 각 4개의 anchor box에 대해서는 21개의 class에 대한 object일 확률 값 ( classification )과 4개의 좌표 x, y, w, h에 대한 Default box와 GT간의 offset 값 ( regression )이 들어있습니다. 다음 정보를 바탕으로 detection에 활용하는 것이죠.

구체적으로 저런 고양이 강아지 사진이 있을 때, 8x8에서는 2번째 그림과 같이 anchor box들이 구축되는데, 고양이 부분에서 파랗게 표시된 부분이 바로 GT와 매칭된 anchor box를 의미하게 됩니다. 매칭 기준은 IOU 50% 이상을 기준으로 판별합니다. 반면 8x8에서는 강아지가 detect되지 않지만 4x4에서는 detect되는 것을 확인할 수 있습니다. 이 매칭 박스 정보로 classification을 수행하며 이 매칭 박스는 GT와 가까워지기 위해 계속 offset 값을 계산하면서 Bbox regression을 수행하게 됩니다.
이 task를 수행하기 위한 loss function은 다음과 같이 디자인됩니다.

Faster RCNN과 마찬가지로 Bbox Regression에서는 smooth 함수를 사용해서 loss를 계산하였습니다.

이렇게 나온 SSD의 성능은 아래와 같습니다.
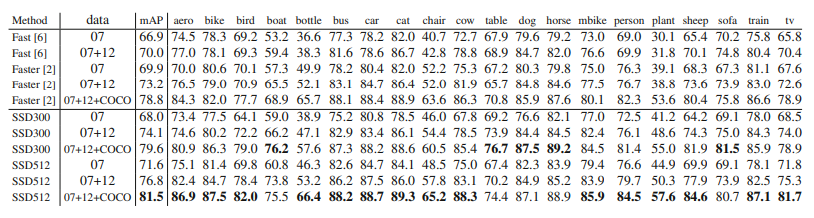

위 도표는 PascalVOC 2007, 아래는 PascalVOC2012에 대한 성능 결과입니다. 결과는 뭐 단연 SSD가 가장 우세한 것을 확인할 수 있었습니다. 속도도 확인해보겠습니다.

성능이 우수하면서도 다른 알고리즘에 비해 우수한 detection 성능을 가짐을 알 수 있었습니다.
하지만 SSD는 조금 치명적인 단점을 가지고 있습니다.
바로 'Data augmentation'의 의존도가 매우 크다는 점입니다. ( 작은 object에 대한 성능 향상을 위해 )

위 그림에서 알 수 있듯, data augmentation만 제거해도 성능이 확 감소함을 알 수 있습니다. 이는 one-stage detection 알고리즘이 갖는 본질적인 문제인 작은 object에 대한 detecting이 어려운 부분이 존재하기 때문입니다. SSD는 이러한 문제를 극복하기 위해 조금 복잡한 data augmentation 방법을 사용하는 것이 특징입니다. ( 특정 IOU 기준으로 filter해서 sampling해가지고 다시 ratio 맞추고 좀 복잡합니다.. ) 아무튼 이러한 복잡한 방법에 의존하는 것은 조금 아쉬운 부분이라고 할 수 있습니다.
다음으로는 YOLO에 대해 정리해보겠습니다.
You Only Look Once
YOLO는 One stage detector의 지평을 열었다고 할 수 있는데요. One Stage detector의 흐름들을 정리해보면 다음과 같이 정리할 수 있습니다.
- YOLO-v1 (2015.06) : Faster RCNN 대비 faster, 성능 worse
- SSD (2015.12) : Faster RCNN 대비 성능, 속도 better
- YOLO-v2 (2016.12) : SSD와 대등한 성능 수행, Inference 속도 SSD보다 빠름
-------- FPN ( Feature Pyramid Network ) 등장 --------
- Retinanet (2017.08) : FPN 처음 적용, detection 성능을 매우 개선하였지만 inference 속도가 SSD보다 느림
- YOLO-v3 (2018.04) : v2 대비 속도, 성능 better
- EfficientDet (2019.11) : YOLO v3 대비 속도, 성능 better
- YOLO-v4 (2020.04) : v3 대비 속도, 성능 better, 성능은 EfficientDet과 유사, 속도는 더 better
현재는 YOLO-v5까지 나온 상황이고 이 외에도 더 다양한 모형들이 존재하지만, 사실상 일각에서는 YOLO가 one-stage detector의 대명사로 보고 있습니다.
자 그렇다면 YOLO-v1 부터 하나씩 살펴보겠습니다
YOLO-V1
YOLO에서 기본적으로 setting하는 것은 cell 단위로 이미지를 나누는 것입니다. 예를 들면 아래 강아지 이미지는 7x7 cell로 구성되는 것을 확인할 수 있습니다.

예를 들어 위의 이미지는 7x7 grid로 나누게 되고 각 grid의 cell이 하나의 obejct에 대한 detection을 수행하게 됩니다. 구체적으로는 각 grid cell이 2개의 bounding box의 후보를 도출하게 되고 그 bbox들을 실제 ground truth에 근사시키면서 학습을 수행하게 됩니다.

예를 들어 저 빨간색 cell에 해당하는 부분에 대한 bbox가 보라색처럼 표기가 되면, 이들이 2개의 bbox 후보가 될 수 있습니다. 이들을 녹색 GT를 바탕으로 근사시키면서 학습이 이루어지게 됩니다.
그러면 구체적으로 네트워크의 구성을 살펴보겠습니다.

윗단을 보면 네트워크의 구성을 확인할 수 있는데요. 우선 input image를 입력할 때 backbone 네트워크로는 VGG가 아닌 Inception-v1 (googlenet) 네트워크 기반으로 동작을 수행합니다. Googlenet의 대표적인 특징으로는 1x1 convolution layer를 사용한다는 것이 특징이죠. 1x1 convolution layer는 feature map의 수를 줄여주어 연산량을 줄여주는 효과가 있습니다. 혹시 googlenet에 대한 자세한 정보가 필요하신 분들은 googlenet에 대한 설명이 잘 정리되어 있는 아래 블로그를 참고해주시면 좋을 것 같습니다.
[CNN 알고리즘들] GoogLeNet(inception v1)의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com

저렇게 backbone을 통과하고 나면, 2개의 dense layer를 거치게 되는데, 이들은 classification과 regression을 수행하기 위해 적용되는 layer로 볼 수 있습니다. 2개의 dense layer를 거쳐 구성된 "7x7x30" 의 feature map을 구축하게 되고 이들의 information을 활용해서 Bbox regression과 object detection의 예측을 수행하고 이 결과를 바탕으로 네트워크를 업데이트하게 됩니다.

7x7x30의 정보를 활용한다는 것이 어떤 의미일까요? 위 그림을 자세히 보시면, 예를 들어 저렇게 7x7x30의 feature map에서 cell 하나를 뽑게 되면, 그 cell 하나는 30의 depth를 가지게 됩니다. 그러면 그 30의 depth에는 어떠한 정보를 포함하고 있는 걸까요?
우선 첫 번째로는, cell 당 2개의 Bbox를 가지게 되는데 그 Bbox의 좌표 값과 confidence score를 가지고 있습니다. 좌표는 알고 있듯 ( x, y, w, h )의 정보를 의미하는데, confidence score는 뭘까요? Confidence score는 말 그대로 현재 내가 예측한 bbox가 감싸고 있는 object가 실제 object일 확률과 GT와의 IOU를 곱한 값이라고 할 수 있습니다. 즉 다음과 같이 5개의 정보가 2개씩 들어있기 때문에 우선 10개의 정보가 들어가게 되는 것이죠.
( x, y, w, h, prob(object)*IOU ) x 2
다음으로 Classification을 수행할 때, Pascal VOC의 class 데이터를 바탕으로 학습을 수행하기 때문에 20개의 class 정보를 가지고 있게 되는데, 각 class별로 예측된 확률 값을 내부적으로 가지게 됩니다. 따라서 이 20개의 정보가 추가되어 총 30개의 정보가 cell 별로 담겨있는 것입니다.
자 그렇다면 구체적인 Loss function은 어떻게 구축되는지 봐 봅시다.

자 그럼 저기 있는 내용을 하나씩 뜯어보겠습니다.
우선 맨 처음 2개의 term은 bbox와 관련된 term인데요. 하나씩 살펴보면,

우선 해당 식은 일반적인 중심 좌표의 regression 수식입니다. S^2는 grid cell의 수가 되고 B는 2개의 bbox 후보가 됩니다. 이 때 독특한 점이 지시 함수가 들어가 있음을 알 수 있는데요. 예를 들어 현재 바라보고 있는 Bbox가 'object를 책임지고 있는 bbox이면 1, 아니면 0'을 label하는 것입니다. 즉 모든 bbox를 전부 저 regression을 적용하는 것은 아님을 알 수 있습니다.
예를 들면,

이런 경우에 빨간색만 regression을 취급하겠다는 의미랑 동일합니다.
다음 term의 경우 w, h에 대한 loss 계산인데 저 항이 추가된 이유는, 일종의 standardization을 수행해주기 위함입니다. 예를 들어보면,

다음처럼 A와 B가 있을 때, A의 경우가 더 예측이 좋았지만, 실제 단위의 차이로 인해 B가 더 loss가 적은 경우가 존재합니다. 이를 방지하기 위해 위 term이 존재하게 되는 것입니다.
다음으로는 남은 2개의 term인 classification 부분을 살펴보겠습니다.

저 수식에서는 예측된 Object confidence score와 GT의 IOU의 예측 오차를 기반으로 구성됨을 알 수 있는데요. 신기한 점은, 위 수식에서 2번째 term이 추가되어있다는 점입니다. 즉, Object를 책임지는 Bounding box의 confidence loss와 Object가 없어야 하는 Bounding box의 confidence loss가 같이 구성되어 있다는 점이 특징입니다. 왜 저 2번째 term을 추가했는지는 저도 의문이긴 하네요..
그리고 마지막으로 최종 bbox가 정해지면 이들의 classification에 대한 예측 확률의 오차로 마지막 term이 구성됩니다.

자 그래서 아래 그림처럼 cell 별로 저렇게 예측 bbox들이 형성이 되게 되면 저 친구들을 NMS 방식을 통해 어떤 cell의 어떤 bbox가 명확하게 예측을 수행하는 지를 class 별로 추려내는 과정들을 거치게 됩니다.

하지만 이런 YOLO-v1는 빠르지만 SSD만큼 성능도 잡지는 못했죠. 그래서 Version 2가 등장하게 됩니다.
YOLO-V2
Version 2는 구체적으로 어떠한 부분이 바뀌었을까요?
Feature Extractor : Inception based -> Darknet-19
# of anchor box per grid : 2 ( no anchor box ) -> 5 ( K-means clustering )
Output feature map 크기 : 7x7 -> 13x13
Batch normalization 적용
High Resolution Classifier 적용
예측 bbox의 x,y 좌표가 중심 cell 내에서 벗어나지 않도록 Direct Location Prediction 적용
Classification Layer : FC Layer -> Convolution Layer
이렇게 7가지의 큰 부분이 바뀌었습니다.
우선, feature extractor의 모형이 Inception이 아닌 Darknet-19로 바뀌게 되었습니다. Darknet의 경우는 YOLO의 저자 Redmon이 자체적으로 만든 CNN 네트워크라고 볼 수 있습니다.
다음으로 기존에는 anchor box를 사용하지 않았었는데 version 2부터는 anchor box의 개념을 사용하기 시작합니다. 여기서는 cell 마다 5개의 anchor box가 존재하게 됩니다. 그리고 이 anchor box를 만드는 데에는 k-means clustering이 적용되었다고 합니다.
또한 output feature map이 7x7이 아닌 13x13으로 구성을 하게 되었습니다.
또 Batch normalization 논문이 나오게 되면 이를 적용하게 되었고, 독특하게 여기서는 classification 끝단을 기존처럼 dense layer가 아닌 convolution layer를 그대로 사용하였습니다. 이렇게 되면, size가 고정되지 않아도 input을 넣을 수 있는 장점이 생기게 됩니다. 또한 'high resolution classifier'를 적용하였는데, feature extractor로 feature를 뽑고, classification 학습 시에는 앞선 feature extractor는 freezing해서 학습을 수행하는 방법도 v2에서 적용된 방법이라고 할 수 있습니다.

이제 단순한 bbox가 아닌 anchor box의 개념을 본격적으로 도입합니다. 위 그림처럼 cell 별로 anchor box를 두게 되는데 v2에서는 5개를 할당하였습니다. 그리고 이 anchor box의 크기를 할당할 때에는 k-means 알고리즘을 사용했다고 합니다.

이렇게 구축이 된 YOLO-v2의 네트워크를 통과하고 나면 구성되는 feature map의 크기는 13x13x125가 되는데, 여기에서는 어떠한 정보가 포함되는 지를 확인해보겠습니다.


여기서는 v1과 마찬가지로 앞선 25개의 정보를 포함하고 있습니다. 하지만 고정된 5개의 anchor box마다 정보를 가지고 있기 때문에 25x5로 총 125개의 채널이 구축됨을 알 수 있습니다.
다음으로는 'direct location prediction' 개념을 살펴보겠습니다.

위 식을 보면 업데이트를 하는 과정에서 기존 중심 좌표를 변경시킬 때 더해지는 tx, ty 값에 sigmoid를 취함을 알 수 있습니다. 또한 w, h 업데이트 식에도 e^(tx), e^(ty)를 곱해주는 형태가 있음을 알 수 있는데요. 이 식의 의미는 아래 위 그림에서 나오는 그래프처럼, 중심 좌표 x,y가 주어진 cell 밖을 벗어나지 않게끔 조정을 하는 것을 의미하게 됩니다. 그래서 cell 별로의 anchor box라는 특징을 놓치지 않게끔 설계한 것을 알 수 있습니다.
그래서 이러한 특징을 반영해서 YOLO-v1의 loss에 저 direct location prediction을 추가해주었습니다.
다음에 feature extractor 부분에서 조금 특이한 구조를 추가하였는데 이는 바로 ‘Passthrough module’을 사용한 ‘fine grained feature’를 도출하는 부분입니다. 그림을 살펴보겠습니다.

feature extractor를 통과함으로서 feature map이 줄어들면 줄어들수록, 즉 추상화될수록 큰 object에게는 유리하지만 작은 object에게는 detection 시 불리하게 됩니다.
그래서 그러한 부분을 보완하기 위해 작은 이미지에 대한 상세한 특징을 더 가져가기 위해, pass through 특징을 사용하게 되는데요. 위 그림에서 중간에 26x26x512에서 13x13x1024로 줄여나가는 과정에서 추가적으로 26x26x512를 reshape해서 13x13x2048 정보를 추가로 만들어내어 이를 앞선 convolution 연산을 적용한 13x13x1024에 추가해주는 과정을 거칩니다. 그럼으로써 13x13x3072의 feature map이 나오게 됩니다. 이러한 단계를 V2는 추가해주었다고 합니다.

그리고 기존 googlenet이 아닌 DarkNet-19라고 하는 독자적인 backbone 모델을 디자인하였는데, 끝단은 dense layer가 아니라 convolution layer를 사용함으로써 동적 이미지 크기 할당을 가능하게 하였고, 기존 VGG16이나 YOLO-v1에서 사용한 수정된 inception 이 갖는 연산량보다 훨씬 적은 연산량으로 더 높은 성능을 내는 backbone 모형을 구축했다고 합니다.

그래서 version 1 대비 추가된 아키텍처들을 대상으로 ablation study를 해보면 다음과 같이 나옵니다. 모든 구성요소들이 어느 정도의 performance에 기여하는 것을 확인할 수 있습니다.
이렇게 version2는 보다 성능을 개선함을 확인할 수 있습니다. SSD보다도 더 좋은 성능과 빠른 성능을 도출하게 되었네요.

마지막으로 version 3를 정리해보겠습니다.
YOLO-V3
앞서 언급드렸듯 version 3부터는 Feature Pyramid Network이라고 부르는 FPN의 개념을 적용하기 시작합니다.
FPN에 대해서 간단하게 설명드리면 다음과 같습니다.

우선 일반적인 input이 들어오면 다음과 같은 convolution 을 통과하면서 feature map이 구축됩니다. 그 다음으로 예측 task를 통과할 때 저 feature 정보만이 아니라, 이전에 구축되었던 상위 단계의 feature map 들을 같이 merge해서 predict 연산을 수행합니다. 저 merge 단계가 없다면 기존 SSD에서 수행한 multi-level feature 연산과 다르지 않지만 저 merge 단계를 수행하는 부분을 통개 보다 추상적인 정보와 보다 상세한 정보를 같이 활용하는 장점을 가지게 됩니다. merge를 하기 위해서는 size가 맞아야 하는 부분이 필요하기 때문에 더 낮은 단계에서 상위 단계와 size를 맞추기 위해 2배로 upsampling하는 단계를 수행해줍니다.
Version 3는 그러면 2에 비해 어느 부분이 구체적으로 바뀌었을까요? 다음과 같이 정리할 수 있을 것 같습니다.
- FPN 도입
- Output Feature Map 크기 : 13x13 -> { 13x13, 26x26, 52x52 3개 사용 }
- Anchor box 수 : 5개 -> Output feature map 1개당 3개, 즉 총 9개
- Feature Extractor : Darknet-19 -> Darknet-53 ( Resnet 대응하기 위해 )
- Multi Label 예측을 위해 softmax가 아닌 sigmoid 기반의 다량의 logistic classifier로 개별 object의 multi label 예측
저 FPN 부분을 잘 표현한 도식도를 가져오면 다음과 같습니다.

위 수식에서 DarkNet-53 backbone을 사용하는 구조입니다. 맨 왼쪽 상단의 '+' 부분이 바로 Skip connection을 수행해주는 부분입니다. ( Skip connection은 Residual learning의 개념으로 본 개념에 대해 낯선 분들은 아래 블로그 링크 'ResNet'을 참고해주시면 좋을 것 같습니다 ). 저기서 왼쪽 상단에 처음 36번째 layer와 61번째 layer 그리고 79번째 layer에서 도출되는 feature map 정보를 바탕으로, 먼저 79번째 layer에서 쭉쭉 진행해 82번째 layer에서 도출된 강아지 feature (13x13) map이 도출된 것을 확인할 수 있습니다. 그리고 더 convolution 연산을 진행하다 이를 2배 up sampling을 해준 다음에 61번째 layer에서 뽑은 것과 merge를 수행해줍니다. 다음으로 94번째 layer를 통해 도출된 강아지 feature map (26x26)이 도출됨을 확인할 수 있습니다. 그리고 마찬가지로 2배 upscaling을 해주어 상위 레벨인 36번째 layer를 통과한 size의 데이터와 merge를 시키고 연산 끝에 마지막 106번째 layer를 통과한 강아지 feature map (52x52)가 구축되게 됩니다. 즉, 이렇게 3개의 output feature map ( 13x13, 26x26, 52x52 ) 이 도출됩니다.
그리고 각 feature map의 정보들은 앞선 version 2와 동일하게 됩니다. 다만 anchor box가 3개기 때문에 depth는 75개가 되겠군요.
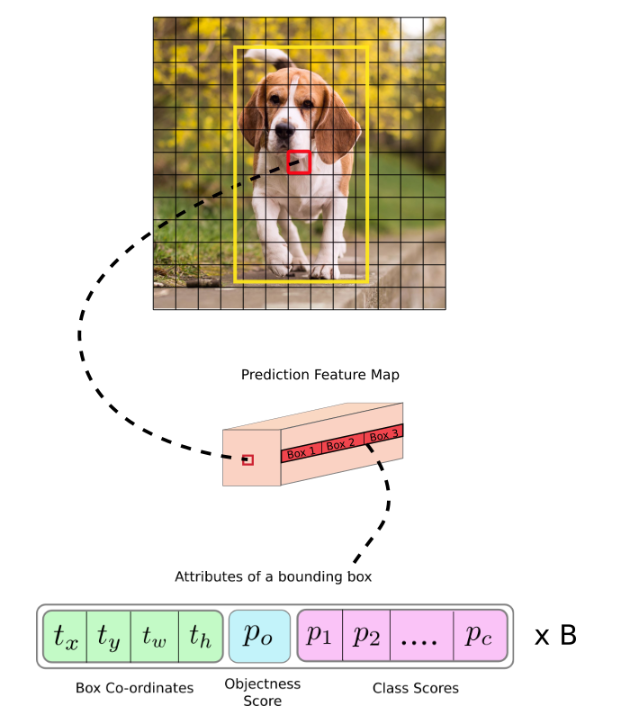
그리고 Darknet-53의 경우는 당시 가장 핫했던 ResNet을 이기기 위해 독자적인 backbone 모형을 만드는데 여기서도 ResNet의 근간이 되는 skip connection을 사용합니다. 다만 깊이가 훨씬 얕은 53개의 layer만 사용하고도 더 좋은 퍼포먼스와 속도를 가지게 되었습니다.


마지막으로 재밌는 그래프를 도입하는데요. YOLO-v3는 앞선 모형들 대비 앞도적인 수행 속도를 가지고 있으면서 detection 성능이 그렇게 나쁘지 않는 준수한 성능을 보임을 확인할 수 있습니다. 바로 이러한 부분이 version 3가 갖는 특징입니다.
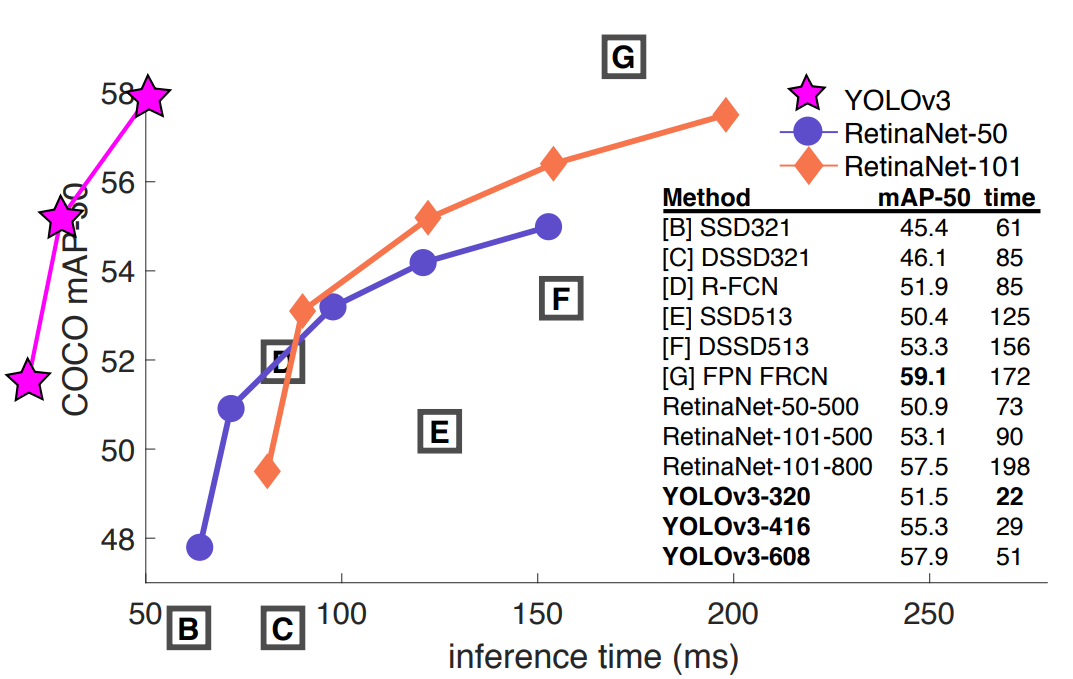
version 4, 5는 추후에 기회가 되면 추가로 정리하겠습니다..!
이상 SSD와 YOLO-v1,v2,v3에 대한 리뷰를 마치겠습니다.
개인 공부용으로 정리된 것이다보니 정리가 말끔하지 않은 점은 양해부탁드립니다.
긴 글 읽어주셔서 감사합니다.
참고 : ResNet 공부 링크
[CNN 알고리즘들] ResNet의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
'ML & DL & RL' 카테고리의 다른 글
| [Deep learning] Sequence Modeling (0) | 2022.09.22 |
|---|---|
| [ Computer Vision ] Object Detection - RetinaNet & EfficientDet (2) | 2022.07.09 |
| [ Computer Vision ] Object Detection - RCNN, Fast RCNN, Faster RCNN (0) | 2022.06.23 |
| [Reinforcement Learning] Alphago, MCTS (0) | 2022.06.13 |
| [Reinforcement Learning] Policy based RL - Policy Gradient, REINFORCE algorithm, Actor-Critic (2) | 2022.06.10 |



