
No Limitation
[ Computer Vision ] Object Detection - RetinaNet & EfficientDet 본문
[ Computer Vision ] Object Detection - RetinaNet & EfficientDet
yesungcho 2022. 7. 9. 19:38본 포스팅은 개인 학습용으로 작성되었고 권철민 님의 '딥러닝 컴퓨터 비전 완벽 가이드' 강의 내용을 참고하였습니다.
이번 포스팅은 One-stage Detector의 강력한 성능을 자랑하는 RetinaNet과 다양한 속도와 성능을 개선한 아키텍처들을 제안하는 EfficientDet에 대해 정리해보고자 합니다.
먼저 RetinaNet부터 살펴보겠습니다.
RetinaNet
원 논문 링크 : https://openaccess.thecvf.com/content_iccv_2017/html/Lin_Focal_Loss_for_ICCV_2017_paper.html
Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980-2988).
RetinaNet의 경우 사실상 거의 One-Stage Detector 중 가장 detection 성능이 뛰어난 모형으로 알려져 있습니다. 하지만 수행 속도가 YOLO나 SSD보다는 느리다는 단점은 있지만 two-stage detector인 Faster-RCNN보다 빠른 장점이 있죠.
이전 YOLO나 SSD는, 물론 SSD 논문에서는 Faster-RCNN보다 더 성능이 좋았다는 얘기는 하지만, 실제적으로 Faster-RCNN이 일반적인 task에서 더 성능이 좋은 경우가 부지기수였습니다. 하지만 RetinaNet이 등장하면서 비로소 Faster-RCNN보다 detection 성능이 더 좋은 알고리즘이 등장했다고 볼 수 있습니다.
특히 RetinaNet은 One stage detector의 고질적인 문제점인 작은 object에 대한 detection이 매우 좋았음을 알 수 있습니다.

YOLO-v3 에서 보았던 이 그림이 본래 RetinaNet 논문에서 나왔던 그림입니다. 보시다시피 inference 속도는 YOLO나 SSD보다 느리지만 AP 성능은 매우 우세함을 알 수 있습니다. 이후 YOLO-v3가 나오면서 저 사진에 자신들의 퍼포먼스를 그래프에 추가해서 속도가 매우 빠르다는 것을 강조하는 그림을 넣었었죠.
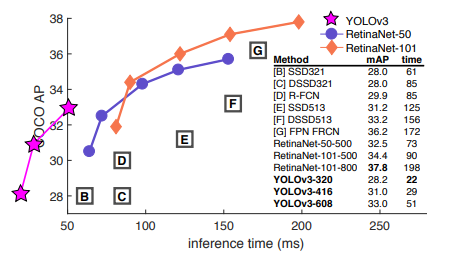
자, 그럼 RetinaNet은 어떠한 방법으로 아주 우수한 detection 성능을 가지게 되었을까요? RetinaNet은 다음 2가지 기법을 사용하였습니다. 이는 추후에 많은 detection 알고리즘들에 영향을 주었습니다.
- Focal Loss
- Feature Pyramid Network 차용
그럼 각각의 요소에 대해 살펴보도록 하겠습니다.
Focal Loss
Focal loss는 cross entropy loss의 변형 꼴로 가중치 값을 준 경우를 의미하게 되는데, 왜 굳이 가중치를 주는 지에 대해 살펴봅시다.
우리가 알고 있듯, cross entropy는 그 class에 속할 확률이 어느 정도인지에 따라 loss 값이 결정되게 되죠.
예를 들어 아래 그림을 보시면,

2개의 모형 NN1과 NN2가 있다고 했을 때, 각 모형의 실제적인 오차율은 0.33으로 동일하지만 그들이 판단을 내린 '확신'의 정도로 보았을 때는 NN1이 훨씬 좋은 모형임을 알 수 있습니다. 실제로 그 정도를 반영해주듯, cross-entropy의 값도 NN1이 0.38로 훨씬 적음을 알 수 있습니다.
그래서 ‘확신’의 정도에 다른 어느 정도 loss가 결정되게 되는 논리가 바로 cross entropy에 적용이 되는데요.
하지만 이러한 지표가 반영하지 못하는 부분이 바로 ‘class imbalance’ 문제입니다.

예를 들어서 다음 그림을 보시면, 탐지한 object는 사람(person)과 연(kite)에 대한 object를 detect하게 되지만, 실제적으로는 많은 background example들이 존재하게 됩니다. 예를 들어 위 그림에서 60x80의 feature map이 생겼다고 대강 생각해본다면 각 grid 별로 anchor box를 그리게 될 때, 대부분 background에 대한 정보를 가지게 될 겁니다. 특별한 경우가 아니면 보통의 경우는 그 정보가 많을 수 밖에 없으니까요. 그래서 대부분의 class imbalance 문제에서 그렇듯, object detection에서도 모형이 background를 잘 맞추기 위한, 즉 우리의 관심사가 아닌 부분을 잘 맞추려고 업데이트가 되는 문제가 발생하게 되는 것이죠.
보통 object detection task에서는, background나 크고 선명한 object 같은 찾기 쉬운 object들을 easy example이라고 하며 이들은 이미 높은 예측 확률을 가지고 있습니다. 반면 hard example은 찾기 어려운 대상들로서 작고 형태가 불분명해서 낮은 예측 확률을 가지고 있는 것이 특징입니다.
이러한 class imbalance 문제는 two-stage detector에서는 그다지 큰 문제가 되지 않습니다. 왜냐하면 1차적으로 region proposal을 수행한 다음에 detect task를 수행하기 때문입니다. 하지만 one-stage의 경우는 한 번에 수행되어, 모든 anchor box에 대한 업데이트가 수행되기 때문에 background에 대한 업데이트도 같이 이루어져 이 문제에 봉착하게 됩니다. 그래서 퍼포먼스가 two-stage detector에 비해 우수하지 못했던 것도 이러한 이유였습니다.
조금 더 이해를 돕고자 다음 예시를 들어보겠습니다.

10,000개의 easy example에 대한 예측 확률이 0.8, 그로 인한 loss를 0.1로 하고
50개의 hard example에 대한 예측 확률이 0.3, 그로 인한 loss를 2라고 하면,
각각으로 인한 loss는
10,000 x 0.1 = 1,000
50 x 2 = 100
이렇게 구성된다.
loss의 경우 easy example이 더 크게 되므로 easy example을 더 잘 맞추려는 경향으로 업데이트가 된다.
하지만 우리의 화두는 easy example이 아닌 hard example을 더 잘 맞추려는 방향으로 업데이트해야 하는데 그러한 방향으로 업데이트가 되지 않는 문제가 발생한 것이다.
바로 RetinaNet은 이 부분을 'Focal Loss'를 통해 극복하고자 했습니다.
Focal Loss의 수식을 보면 아래와 같습니다.
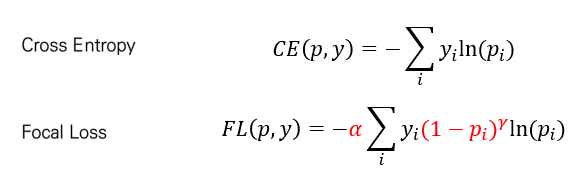
기존 cross entropy와 다르게 빨간색의 수식이 더 추가 됨을 알 수 있는데요. 알파는 hyperparameter고 실제적인 가중치 역할을 하는 부분이 바로 시그마 안에 있는 빨간색 term 입니다.
저 수식의 의미는 예를 들어, pi = 0.99로서 굉장히 확실한 예측을 하게 된다고 하면, 이에 대해 가중치 (1-0.99)^2 ( 감마 값을 2로 하면 ) 값이 곱해져서 작은 가중치가 부여됩니다. 즉, 이 말은 더 높은 예측 확률로 예측하는, 즉 easy example에 대해 loss가 쏠리게 되는 현상을 막고자 작은 가중치를 곱해지게끔 설계하는 조치를 취하게 된 겁니다.
그래서 예를 들어 p=0.99라고 하게 되면 본래
CE(foreground) = 0.01
CE(background) = 0.01
이었던 loss가
FL(foreground) = 0.00000025
FL(background) = 0.00000025
CE 대비 40,000배 작은 loss 값이 되고 반대로
p=0.1 같은 hard example이라고 하면
CE(foreground) = 2.3025
CE(background) = 2.3025
이었던 loss가
FL(foreground) = 0.4667
FL(background) = 0.4667
로서 5배 정도 줄긴 하지만 그 감소하는 정도가 확 낮아지게 됩니다.
그래서 더 hard example의 loss에 가중치를 줄 수 있는 것입니다.
바로 이 방법이 Focal Loss의 원리입니다.
Feature Pyramid Network
다음에 RetinaNet이 가져온 논리는 바로 FPN입니다.
FPN는 알다시피 '서로 다른 크기를 가지는 object들을 효과적으로 detection하기 위하여 bottom up과 top down 방식으로 추출된 feature map들을 lateral connection으로 연결하는 방식'을 의미합니다.
축약된 feature map과 중간 중간에 있는 level의 feature map도 같이 fusion해서 정보를 활용해서 task를 수행하게 되고, 이를 통해 정보 손실을 막는 것을 목표로 합니다. 정보 손실을 막기 위한 방법으로 ResNet의 'skip connection' 방법을 차용합니다.

이 FPN 구조를 사용한 아키텍처는 다음과 같습니다.

백본으로는 ResNet을 사용하였고 각 level별 feature map 별로 skip connection을 통해 feature를 fusion해주게 되면 그 fusion된 값으로 classification와 regression net에 input으로 보내주는 방법으로 동작하게 됩니다.
조금 더 구체적으로 뜯어보면 다음과 같습니다.

왼쪽의 resnet을 돌리면서 각 level의 feature map마다 1x1 conv를 통과한 다음, 이전 level과의 fusion을 해주기 위해 2배로 upsampling을 수행해주고 각각의 stage마다 fusion된 값들에 3x3 conv를 통과하여 예측 task를 수행하게 됩니다.
저기서 fusion이후 예측 네트워크에 들어가기 전 3x3 conv연산을 수행해주는 이유가 무엇일까요? 이 경우 2개의 서로 다른 signal이 섞이면 혼동되기 때문에 본래 가지고 있던 자신만의 특성을 잃을 수 있다고 합니다. 따라서 이 정도를 희석시키기 위해 3x3 conv 연산을 수행했다고 저자는 언급하고 있습니다.
그리고 저 P1, ... , P5로 구축된 feature map에 anchor box를 바탕으로 classification, regression task를 수행합니다. RetinaNet의 경우 매우 많은 anchor box를 두게 되는데 약 1백만 개의 anchor box를 가지고 있다고 합니다.
여기까지 RetinaNet에 대해 알아보았습니다. 다음으로는 EfficientDet으로 넘어가 보겠습니다.
EfficientDet
Tan, M., Pang, R., & Le, Q. V. (2020). Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10781-10790).
EfficientNet 원 논문 링크 :
https://arxiv.org/pdf/1905.11946.pdf
Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning (pp. 6105-6114). PMLR.
우선, EfficientDet을 이해하기 전에, backbone으로 사용되는 EfficientNet과 그 특징인 'Compound Scaling'을 이해하기 위해 이들 개념이 잘 정리된 블로그 포스팅을 따로 공유합니다. 본 포스팅에서도 간략히 다루지만 자세한 내용은 아래 블로그 링크를 참고하시면 좋을 것 같습니다.
https://hoya012.github.io/blog/EfficientNet-review/
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 리뷰
ICML 2019에 제출된 “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” 논문에 대한 리뷰를 수행하였습니다.
hoya012.github.io
이 EfficientDet을 이해하기 위해서는 크게 2가지 측면을 생각할 수 있는데, 바로 BiFPN의 개념과 Compound Scaling을 적용했다는 점이 가장 큰 특징입니다.
자 우선 이들을 들어가기 전에 EfficientNet에 대한, 특별히 compound scaling 개념에 대해 간략히 짚고 넘어가겠습니다.

EfficientNet에서 주장하는 바는 바로 Image classification을 수행하는 부분에서, 일반적으로 네트워크를 개선해서 성능을 늘릴 때 고려되는 주요 사항으로 ‘depth’, ‘width’, ‘image resolution’가 있다고 언급합니다. 모형의 complexity나 size를 키워서 성능을 높일 수 있는데 그러한 방안으로 이들을 키우는 방향으로 접근했다는 것입니다. depth는 말 그대로 네트워크의 layer 수이며 이러한 대표적인 방법으로는 ResNet이 있습니다. 또한 width는 채널 수를 의미하는데 채널 수를 늘림으로써 성능을 개선한 사례로는 MobileNet이나 ShuffleNet 등이 있습니다. 또한 일반적으로 image의 resolution을 높임으로써 성능을 더 개선할 수 있다는 부분을 언급합니다. 조금 더 구체적인 실험을 진행하였는데요. 아래 그림과 같습니다.
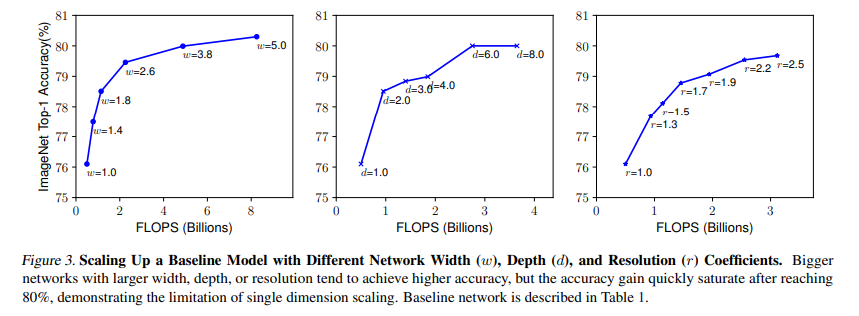
첫 번째 그림은 width, 두 번째는 depth, 세 번째는 resolution을 각각 개별적으로 증가시켰을 때의 accuracy가 어떻게 되는 지를 보여줍니다. width나 depth의 경우 80% 이상의 성능 부근에서는 개선이 잘 되지 않음을 보여주고 resolution의 경우는 점진적으로 성능이 증가함을 알 수 있습니다.
바로 이 점에 착안하여, EfficientNet은 저 세가지 요소를 적절히 조합해서 개선할 수는 없을까를 고민하게 되었습니다.

그 방안으로서 위 제약식을 활용합니다. 위 depth, width, resolution의 3가지 scaling factor를 동시에 고려하는 방법을 적용하기 위해 다음과 같이 d, w, r를 phi에 대하여 정의를 해주고, 처음에는 phi를 1로 고정한 다음에, 알파, 베타, 감마 값을 grid search 기반으로 변화시켜나가면서 FLOPS 변화 값을 바탕으로 최적의 값을 찾아줍니다. 그렇게 찾아진 최적 값들이 나오게 됩니다. 예를 들어 EfficientNetB0의 경우는 알파 값은 1.2, 베타 값은 1.1, 감마 값은 1.15로 가지게 됩니다.
그리고 알파, 베타, 감마 값을 고정하고 나면, 이제 phi 값을 증가시키면서 EfficientB0부터 B7까지의 모형을 도출하게 됩니다. 이 모든 연산을 수행할 때마다 위 수식의 제약식을 늘 만족시켜야 합니다 ( 제약식에 대한 부분은 논문을 봐도 정확히는 이해가 어렵네요 ㅠㅠ 이 부분에 대해 혹시 아시는 분은 커멘트 남겨주시면 감사하겠습니다 ㅠ ). 이렇게 depth, width, resolution을 같이 scaling하면서 최적의 모형들을 디자인하게 됩니다.
이 EfficientNet 모형들이 갖는 성능을 정리한 그래프는 아래와 같습니다.

B0 ~ B7에서 B0은 속도가 매우 빠른, B7은 정확도가 매우 높은 모형으로서 디자인이 되었습니다. 해당 메소드들은 기존 메소드들보다 더 outperform한 성능을 보임을 알 수 있습니다.
이제 compound scaling이 무엇인지 알았으므로 이제 뒤에서 어떻게 EfficientDet에 적용했는지를 다루도록 하겠습니다.
다시 본론으로 돌아와서 앞서,
"이 EfficientDet을 이해하기 위해서 중요한 특징은 바로, BiFPN의 개념과 Compound Scaling을 적용했다는 점"이라고 말씀드렸습니다.
이제 저 2가지가 어떻게 EfficientDet에서 구성되는 지를 살펴보겠습니다.
BiFPN
FPN을 적용한 RetinaNet이 큰 성능 개선을 보이면서 FPN을 개선하고자 하는 움직임이 많이 등장했습니다. 아래 그림을 보시죠.

먼저 (a)는 앞서 공부했던 일반적인 FPN을 의미합니다. 이후 FPN에서 top down 연산만 하지 말고, 같이 bottom up 연산도 feature level 단위에서 fusion을 해주면서 연산을 하면 더 다양한 level feature의 정보를 반영할 수 있지 않을까하는 움직임이 있었습니다. 이후 다양한 FPN을 개선하는 방법들이 등장하였으며, BiFPN도 그 일환으로 등장을 하게 되었습니다.

특징을 다시 짚어보면 기존 FPN과는 다르게, 원본 feature map의 정보도 같이 반영해서 fusion이 이루어지는 것이 가장 큰 차이입니다. 또한 맨 상위와 하위 level의 feature에서는 top-down에서 bottom-up으로 넘어가는 부분에서는 어차피 동일한 값이 전파되니 굳이 fusion task를 수행할 필요 없어 해당 부분은 제거함을 알 수 있습니다. 이렇게 FPN을 구축해서 기존 FPN보다 더 다양한 정보를 전달하게끔 아키텍처를 설계하였습니다. 또한 기존과 다르게 해당 block들을 여러 개 붙여 repeated한 block으로 연결한 점이 특징입니다.
그리고 이 fusion이 이루어질 때, 그냥 단순하게 합산이 되지 않게 가중치를 부여해서 합을 수행하게 되는데, 이 가중치들은 전부 네트워크를 통해 '학습을 통해 도출된' 가중치들임을 언급합니다.
그래서 이렇게 학습된 가중치를 바탕으로 fusion을 수행할 때 그냥 수행하는 것이 아니라 값이 튀는 현상을 막기 위해 bound를 주게 되는데 다음과 같이 softmax 기반의 가중합을 통해 0~1사이의 값을 갖도록 조절하는 과정을 거칩니다.

예를 들면 다음과 같습니다.

저기서 P6에서 정보들이 넘어갈 때 P6의 중간 파란색 원을 Ptd(6), 그 다음 파란색 원을 Pout(6)이라고 하면 위 수식처럼 값이 구해질 수 있는 것입니다. 저기서 사용되는 w1, w2, w1', w2' ,w3'들은 모두 학습된 가중치들을 의미합니다.

이런 BiFPN을 사용했을 때는, 일반적인 FPN을 사용했을 때보다 더 성능이 좋았고 심지어 속도도 더 빨랐다고 저자는 언급합니다. 성능은 그렇다치는데 아키텍처가 더 복잡해졌음에도 속도가 더 빨라진 것은 다소 의아합니다. 저자는 이 부분에 대한 언급으로 일반적인 FPN에서 prediction network 으로 값을 넘길 때 수행되는 3x3 conv layer 부분을 특별히 'Separable convolution'을 사용하여 연산 복잡도를 낮추었다고 합니다. Separable convolution에 대한 설명은 아래 블로그를 참고해주시면 좋을 것 같습니다.https://eehoeskrap.tistory.com/431
[Deep Learning] 딥러닝에서 사용되는 다양한 Convolution 기법들
기존 2차원 컨볼루션은 세가지 문제점이 존재한다. Expensive Cost Dead Channels Low Correlation between channels 또한, 영상 내의 객체에 대한 정확한 판단을 위해서는 Contextual Information 이 중요하다...
eehoeskrap.tistory.com
다음으로 EfficientDet에서의 Compounding Scaling을 공부해보겠습니다.
Compounding Scaling
앞서 'depth', 'width', 'resolution'에 대한 scaling을 해줌으로써 image classification에 대한 성능을 개선했다고 했습니다. 마찬가지의 논리를 object detection에서도 적용을 하였는데요, 구체적으로 다음과 같이 맵핑이 됩니다.
image resolution → input size
backbone → backbone
width → BiFPN channel / predic network channel
layer → BiFPN layers / predict network layer
총 4가지의 개선이 있었는데요. 우선 backbone은 EfficientNet의 B0~B6의 모형을 그대로 사용하였습니다. 그 다음 depth와 width는 BiFPN의 네트워크에 적용되는 layer 수와 channel 수를 업데이트 함으로써 적용되었는데요, depth의 경우 아래와 같이 설정하였고 width의 경우는 {1.2,1.25,1.3,1.35,1.4,1.45} 를 grid search 함으로써 최종적으로 1.35를 활용하여 scaling 계수로 설정해서 아래와 같은 수식으로 적용하였습니다. W가 width고 D가 depth를 의미합니다.

또한 prediction 네트워크에도 depth와 width가 적용되는데 width는 위 BiFPN과 동일한 수식이고 depth의 경우는 아래와 같이 수식이 적용됩니다.

마지막으로 resolution은 다음과 같이 scaling을 수행하였습니다.
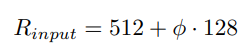
이들을 요약해서 적용한 사례는 아래 그림과 같습니다.

이러한 요소들을 고려해서 최종 모형 D0~D7까지 구성하였습니다.
EfficientDet의 경우는 loss를 RetinaNet의 focal loss를 그대로 사용하였다고 합니다.
이러한 EfficientDet이 갖는 성능은 다음과 같았습니다.

EfficientNet과 같이 대부분의 모형에서 각 단계에 맞게 SOTA 성능을 보였다고 저자는 언급합니다. 다만, 실제로 속도를 나타내는 지표로 사용한 FLOPs가 아니라 inference 속도 측면에서는 YOLO v3보다 빠르다고는 할 수 없다고 합니다. 다만 더 better한 AP 성능을 나타내면서 속도도 개선한 모형을 compounding scaling을 통해 디자인할 수 있다는 점을 저자는 언급합니다.
이상 RetinaNet과 EfficientDet에 대해 정리해보았습니다! 긴 글 읽어주셔서 감사합니다!
'ML & DL & RL' 카테고리의 다른 글
| [Deep-Learning] 2D Convolution operation (2) | 2022.09.24 |
|---|---|
| [Deep learning] Sequence Modeling (0) | 2022.09.22 |
| [ Computer Vision ] Object Detection - SSD & YOLO (0) | 2022.07.02 |
| [ Computer Vision ] Object Detection - RCNN, Fast RCNN, Faster RCNN (0) | 2022.06.23 |
| [Reinforcement Learning] Alphago, MCTS (0) | 2022.06.13 |



