
No Limitation
[Paper Review] An Image is Worth 16x16 WORDS: Transformers for Image Recognition at Scale 본문
[Paper Review] An Image is Worth 16x16 WORDS: Transformers for Image Recognition at Scale
yesungcho 2022. 8. 1. 22:17원 논문
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
https://arxiv.org/abs/2010.11929
본 리뷰는 제 개인 유튜브 채널에도 올려놓았습니다. 참고 부탁드립니다.
https://www.youtube.com/watch?v=5E8nURp3Cec
참고 자료로 고려대학교 산업경영학과 최희정 님의 강의를 참고하였습니다.
https://www.youtube.com/watch?v=0kgDve_vC1o
Introduction
Transformer가 성공을 거두면서 다양한 NLP 내의 task에서 사용되고 있습니다. 하지만 Computer Vision에서는 여전히 ResNet 같은 CNN 기반의 모형이 state-of-the-art를 차지하고 있습니다.
그래서 본 연구에서는 transformer의 아키텍처를 vision에도 도입하는 시도를 하게 됩니다. transformer의 입력 시퀀스의 구조가 이미지와는 상이하기 때문에 구조를 맞추기 위해 저자는 이미지를 sequence로 만들기 위해 패치 단위로 쪼개주는 과정을 거칩니다. 패치로 자른다는 것은 아래 사진과 같은 경우를 의미합니다. 따라서 이 패치들은 NLP의 토큰과 같은 역할을 수행하게 되는 것입니다.

하지만 실험적으로 ImageNet과 같은 상대적으로 작은 데이터셋의 경우는 CNN 기반의 모형이 transformer보다 더 성능이 좋았다고 합니다. 그 이유로 저자는 CNN은 이미지에 대한 'Inductive Bias'가 있다는 점을 언급합니다. 즉, CNN은 filter를 통해 이미지의 local 특징을 잘 분석할 수 있고, 이러한 부분들이 "locality" & "translation equivariance"를 확보할 수 있기 때문에 이미지에 있어서 generality를 확보할 수 있다는 점을 언급하는 것입니다. 본 Inductive Bias에 대한 설명이 잘 나와있는 블로그 링크를 공유해드릴테니 참고하시면 좋을 것 같습니다.
https://re-code-cord.tistory.com/entry/Inductive-Bias%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
Inductive Bias란 무엇일까?
머신러닝에서 Bias는 무슨 의미일까? Inductive Bias라는 용어에서, Bias라는 용어는 무엇을 의미할까? 딥러닝을 공부하다 보면, Bias과 Variance를 한 번쯤은 들어봤을 것이다. Bias는 타겟과 예측값이 얼
re-code-cord.tistory.com
그러면 본격적으로 Method에 대해 살펴보겠습니다.
우선 전체적인 framework는 아래 그림과 같습니다.

ViT는 크게 5가지의 구성 요소로 이루어지는데,
(1) Patch division
(2) Trainable linear projection
(3) Positional Embedding (1-D positional embedding )
(4) Transformer Encoder
(5) Multi-Layer Perceptron (classifier)
다음과 같이 이루어집니다.
그러면 한 스텝 씩 살펴보겠습니다.
Patch division

이 경우 본래 이미지 HxWxC size로 되어 있는 이미지를 transformer 입력으로 넣기 위한 sequence로 바꾸는 과정을 의미합니다.
즉 아래 그림과 같이 N개의 (PxP) 사이즈의 패치로 분할한 것을 raster order로 sequence 형태로 바꾸어주게 됩니다. 그렇게 구축한 xp가 준비되는 것이 첫 번째 단계 patch division입니다.

Trainable linear projection

두 번째 단계로는 Linear projection을 수행해주는 단계입니다. 각 패치마다 linear projection을 통해 flatten한 D차원의 벡터로 만들어주게 됩니다. 그리고 이 flatten vector를 'patch embedding'으로 사용하게 됩니다. 그리고 BERT에서 수행한 것처럼 learnable embedding인 class token을 붙여주게 됩니다.
Positional Embedding (1-D positional embedding )

패치 임베딩까지 수행해주고 나면 transformer에서 하는 것처럼 동일하게 positional embedding을 수행해주게 됩니다. 여기까지가 아래 전체 ViT 부분 중 빨간색 박스에 해당하는 부분입니다. 입력에 들어갈 z0를 준비하고 이를 transformer encoder에 넣어주게 됩니다.

여기서 저자는 몇 가지 실험을 하게 되는데 저 positional embedding을 1-D, 2-D, 3-D 방법으로 다양하게 수행을 하는데, 결론적으로는 1-D positional embedding이 가장 성능이 좋았다고 합니다.

각 embedding을 설명드리면 아래 그림과 같습니다.

앞서 설명드린 것처럼 1-D positional embedding은 raster order로 접근을 하는 방법입니다. 2-D positional embedding의 경우 좌표 정보를 embedding으로 활용하는 것을 의미하며 3-D positional embedding은 좌표 간의 거리를 활용하는 방법입니다. 이렇게 수행했을 때 1-D가 가장 좋은 성능을 보였습니다.
Transformer Encoder
다음으로 ViT의 Encoder를 살펴보겠습니다.

왼쪽의 경우가 ViT의 transformer, 오른쪽이 바닐라 transformer입니다. 자세하게 보시면 구성이 조금 다름을 알 수 있습니다. 기존에는 attention layer를 통과하거나 MLP를 통과한 다음에 skip connection과 normalize를 수행한 반면 ViT에서는 normalize를 먼저 수행하는 특징을 갖습니다. 이 부분을 제외하고 나머지는 전부 바닐라 transformer와 동일한 아키텍처를 갖습니다.
이를 수식으로 표현한 부분은 아래와 같습니다.

저 encoder를 통과한 최종 y는 image representation이 나오게 됩니다. 바닐라 transformer처럼 encoder가 feature extractor 역할을 하는 것이죠.
Multi-Layer Perceptron (classifier)
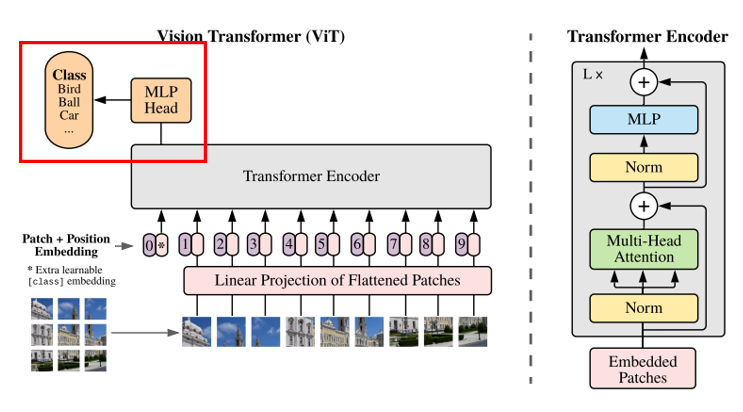
이렇게 y를 사용해서 마지막 MLP layer를 통과하게 되면서, 최종적으로 classification 결과를 도출하게 됩니다.
Hybrid Architecture

여기에 저자는, 원본 이미지에 대한 패치 sequence만 활용하는 것이 아닌 CNN (ResNet) 을 통과한 feature map에서 sequence를 만들어 함께 사용하는 hybrid 아키 텍처도 고안이 가능하다고 언급합니다. 이 경우 이미 feature map 자체에서 공간 정보를 가지고 있기 때문에 패치 사이즈는 1x1로 설정했다고 합니다. 즉, 그냥 바로 D flatten vector로 만들어주어 입력으로 넣게 됩니다.
Fine tuning & Higher Resolution
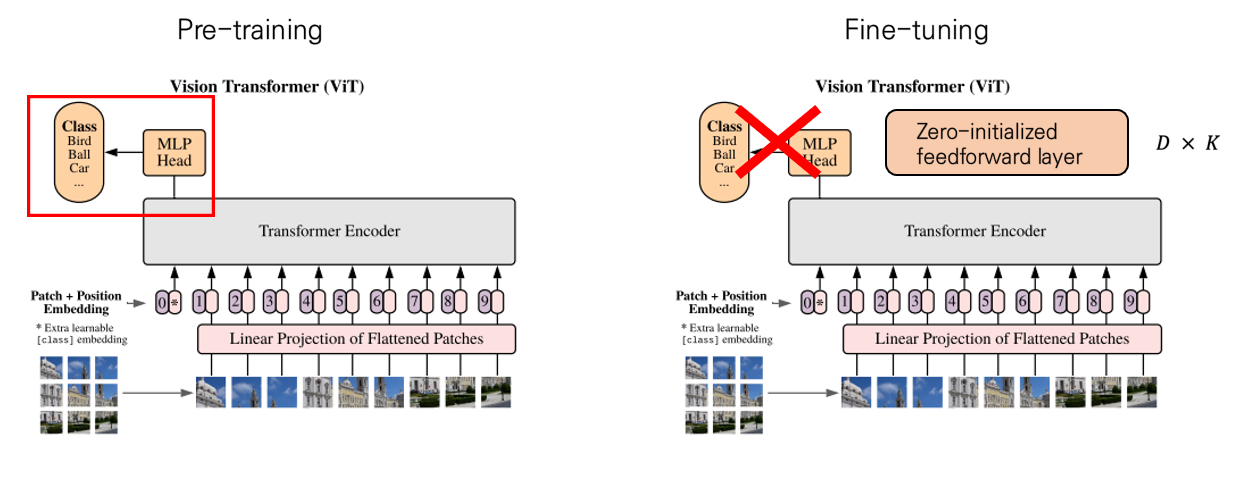
이렇게 학습이 완료되고 나면, downstream task를 수행할 때 task에 알맞은 layer를 뒷단에 붙여주게 됩니다. 즉 fine-tuning시에는 기존 MLP layer를 다시 0으로 초기화된 layer로 바꾸어주어 새로운 데이터셋에 맞게 fine-tuning을 시켜주면 됩니다.

기존 transformer 가 attention을 사용하기 때문에 NLP에서 문장의 sequence 길이가 다른 것에 대해서도 대응이 가능했습니다. 이와 마찬가지로 이미지의 resolution이 다른 것에 대해서도 self-attention이 존재하기 때문에 대응이 가능합니다. 다만, pre-train된 position embedding은 image의 resolution이 달라지면 sequence의 길이가 달라지기 때문에 그 임베딩은 더 이상 useless하게 됩니다. 따라서 이러한 부분을 맞춰주기 위해, 원본 이미지에 2D interpolation을 적용해 줍니다. 이를 통해 resolution에 adjustment한 특성을 가지게 됩니다.
Inductive Bias
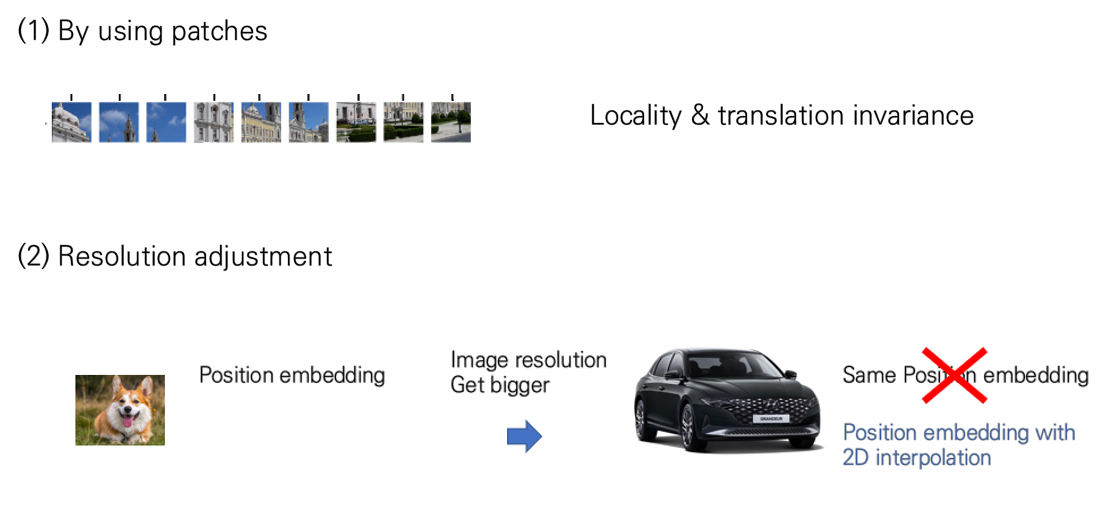
ViT는 앞서 설명드린 설계에 의해, 기존 CNN처럼 'Inductive Bias'를 가질 수 있다고 언급합니다. 특별히 "Patch Division"과 "Resolution adjustment"에 의해 확보가 된다고 합니다. 패치 분할을 sequence로 만듦으로서 locality가 확보가 되며 resolution adjustment를 통해 translation invariance가 확보된다고 저자는 언급합니다.
Experiment
실험에서는 ResNet, ViT, hybrid 3개를 사용했습니다. 저자는 이들의 실험 결과를 통해 이들의 representation learning의 성능을 측정하고자 하였습니다.
그리고 실험의 다양성을 위해 pre-train의 데이터셋의 크기를 다양하게 설정하였고 패치의 크기도 다양하게 설정하였습니다.
구체적으로 pre-train과 downstream task를 수행하기 위한 데이터셋으로는 아래와 같이 사용하였습니다.


ImageNet-1k는 상대적으로 작은 데이터셋이며, JFT는 큰 데이터셋입니다. 이러한 pre-train 데이터셋의 크기에 따라 성능이 어떻게 달라지는 지를 측정하고자 하였습니다.
또한 저자는 ViT를 아키텍처의 크기에 따라 ViT-Base, ViT-Large, ViT-Huge로 나누어 각각의 성능을 측정하였습니다.

또한 비교 집단인 ResNet도 fine-tuning을 해주어야 하기 때문에 transfer learning에 적합하도록 다음과 같은 절차를 수행했다고 합니다. 이를 통해 ResNet을 BiT (Big Transformer) 구조로 바꾸었다고 저자는 언급합니다.
[1] Batch Normalization -> Group Normalization
[2] Using standardized convolutional layer
Comparing SOTA
다른 모형과 classification 성능 비교를 수행한 결과는 아래 표, 그래프와 같습니다.
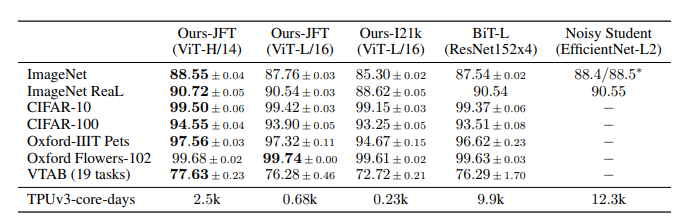

JFT pre-train 데이터셋에서 Huge 모형이 가장 준수한 성능을 보였으며, 19-task VTAB classification suite 데이터에서도 Natural, Specialized, Structured 데이텃세에서 모두 ViT-H 가 가장 우수한 성능을 보였습니다.
Pre-training data requirements
또한 저자는 pre-training 데이터셋의 size가 변함에 따라 어떤 변화가 있는지를 확인하고자 하였습니다. 작은 데이터셋에 있어서는 performance를 향상시키기 위해 weight decay, drop out, label smoothing 같은 regularization을 적용했다고 저자는 언급합니다. 그리고 사이즈가 어느 정도 커진 JFT 데이터셋에는 이러한 regularization을 적용하지 않았다고 합니다.
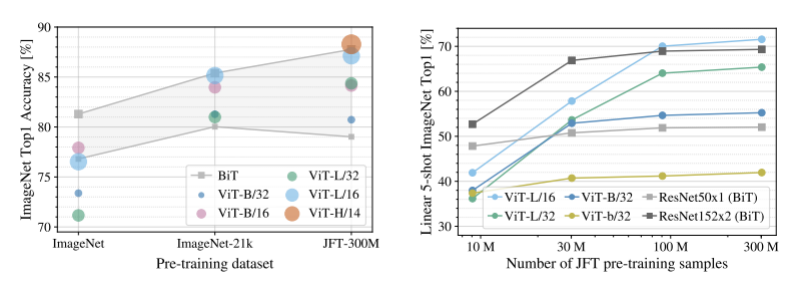
데이터셋이 적은 ImageNet 부분의 경우 Inductive Bias가 확보된 BiT가 outperform함을 확인할 수 있었고 regularization 효과로 상대적으로 ViT-B가 L,H보다 더 outperform한 것을 알 수 있었습니다. 하지만 점차 데이터셋이 커지면서 ViT가 더 큰 outperform한 것을 알 수 있었습니다.
Scaling Study
또한 pre-training 데이터 사이즈가 커지면서 데이터 사이즈가 커짐에 따른 inference 속도 ( pre-training cost )는 어떻게 되는 지를 점검하는 과정을 거쳤습니다.
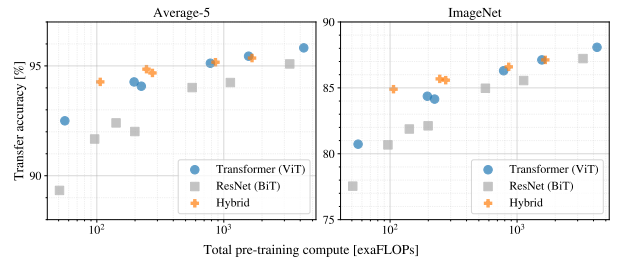
ViT가 performance/compute tradeoff에서 더 outperform한 것을 알 수 있었고 동일한 성능을 내기 위해 2~4배 덜 연산 비용이 들어감을 알 수 있었습니다.
그리고 초반에는 hybrid가 굉장히 연산 효율이 좋았지만 점차 데이터가 커짐에 따라 그 격자가 줄어듦도 확인할 수 있었습니다.
Inspecting Vision Transformer
마지막으로 ViT가 이해한 맥락을 탐색하는 과정을 거쳤는데요. 처음에는 ViT에서 linear projection을 수행한 다음, 이들의 top principal components 들을 시각화를 해보았습니다.

오른 쪽의 경우가 28개의 principal components들의 시각화 결과이고 오른쪽의 경우가 일반적인 CNN 을 통과할 때의 feature map 결과입니다. 보시면 아시다시피 이미지의 추상적인 부분을 뽑아낸다는 점에서 매우 둘의 결과가 resemble한 것을 알 수 있습니다.
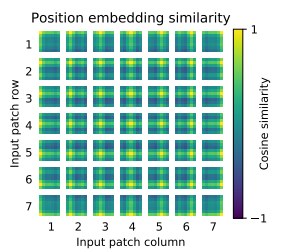
또한 positional embedding이 잘 구성되는 지를 확인하는 과정을 거칩니다. 즉 근접한 position일 수록 더 similarity가 높을 것이기 때문에 이를 시각화한 그래프는 위와 같습니다. 실제 시각화해본 결과 더 가까운 position일 수록 그 simiarity가 유사한 것으로 보아 embedding이 잘 수행되었음을 확인할 수 있습니다.

마지막으로 저자는 ViT가 이미지의 전반적인 정보에 대해서 잘 이해하고 있는 지를 확인하는 과정을 거칩니다. 특별히 self-attention을 통과하면서 attention head의 가중치 값들의 'average distance'를 구함으로써 이들이 이미지 전반의 정보를 잘 포함하는 지를 확인하는 과정입니다. 즉, 너무 국지적인 정보만 캐치하고 있지 않는 지를 확인하는 것입니다. 그래서 이 'average distance'는 CNN의 'Receptive field'랑 동일한 기능을 수행하게 되는 거죠.
즉, lower layer에서의 distance 값을 보면 낮은 layer에서도 distance가 큰 경우가 있는, 즉 정보를 잘 캐치하게 되는 부분이 존재하게 되는 것입니다.
이상 ViT 리뷰였습니다. 긴 글 읽어주셔서 감사합니다!
( 혹 리뷰에 이상한 부분이나 틀린 부분이 있으면 언제든 크리틱 부탁드립니다! )



