
No Limitation
[Paper Review] OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representation 본문
[Paper Review] OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representation
yesungcho 2022. 6. 1. 16:53원 논문 링크 :
Perera, P., Nallapati, R., & Xiang, B. (2019). Ocgan: One-class novelty detection using gans with constrained latent representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2898-2906).
본 논문 리뷰는 영상으로 제 개인 유튜브 채널에도 올려놓았습니다. 참고 부탁드립니다.
https://www.youtube.com/watch?v=sIEERLxx5kk
Introduction
이상치 탐지에서는 많은 연구들이 수행되고 있습니다. 딥러닝이 발전하면서 이상치 탐지 영역에서도 연구들이 많이 수행되었는데, 다른 학습과는 다르게 이상치 탐지는 학습된 데이터에서 발견되지 않는, 혹은 거의 없는 데이터셋에 대한 예측을 수행해야 하기 때문에 일반적인 분류 task와는 결이 다릅니다. 그래서 이상치 탐지를 out-of-distribution, 즉 우리가 알고 있는 분포에서 벗어난 샘플을 예측하는 task로 부르기도 합니다.
그러면 우리가 알고 있는 데이터의 경우 in-class, normal, regular 등등 많은 용어로 부르지만, 즉 우리가 평소에 늘 얻을 수 있고 관찰할 수 있는 일반적인 상황에서, 이 데이터에 대한 distribution이나 feature를 정확히 알아야만, out-of-class를 잘 detect할 수 있을 것입니다. 그래서 이상치 탐지에서 자연스럽게 'Representation Learning'을 바탕으로 한 여러 방법들이 도입되어 왔습니다. 그 중 많이 연구가 이루어진 분야는 바로 오토인코더(autoencoder) 기반의 재구성 오류(reconstruction error)를 바탕으로 이상치를 판단하는 것입니다. 아래 그림을 보시죠.
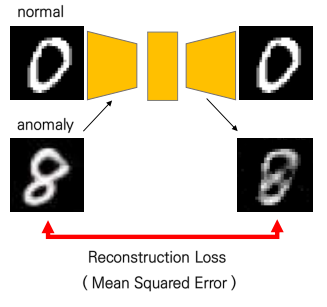
오토인코더 기반 구조에서, 위에처럼 0이 normal인 경우, 8인 경우를 anomaly로 가정해보겠습니다. 0인 경우는 우리가 오토인코더를 학습할 때 사용한 데이터이기 때문에 새로운 0이 들어오면 그 특징을 잘 뽑아내어 구성을 잘 할 것입니다. 하지만, 만약 normal과는 특징이 다른 anomaly가 들어오게 되면, 그 특징이 다른 무언가가 들어오면, 구성을 잘 하지 못할 것입니다. 바로 이 차이, 이 재구성을 했을 때의 차이 값인 reconstruction error를 바탕으로 anomaly를 detect하게 됩니다.
하지만 아쉽게도 이 원칙이 늘 맞는 말은 아닙니다. 저자는 바로 이 부분을 지적합니다.
아래 그림을 보시죠. 아래 그림은 본 논문을 가장 잘 나타내는 그림이라고 볼 수 있습니다.

"8" 이미지를 normal이라고 가정해보겠습니다. 8에 대한 오토인코더는 잘 generate하겠지만, 상대적으로 8이 아닌 다른 글씨의 경운느 잘 생성을 못해야 합니다. 하지만 위 그림에 나와있듯, 1, 5, 6, 9 같은 경우도 오토인코더가 매우 잘 generate하는 것을 알 수 있습니다. 이상합니다. 한 번도 본 적이 없는 샘플들이고 8만 학습했는데 어떻게 나머지 클래스의 숫자들을 generate할 수 있었을까요? 바로 8과 같이 비교적 복잡한 object의 경우 latent space 내에서 in-class만이 아닌 out-of-class의 feature들의 특징도 가지고 있었기 때문입니다.
이를 조금 더 명확하게 설명한 것은 아래 그림과 같습니다.

잠재 공간 내 8과 8를 잇는 어떠한 path를 골랐다고 해봅시다. 이러한 오토인코더에 1의 이미지를 넣게 되면 위 그림에 나와 있듯 1이 잘 생성됩니다. 8이 형성하는 공간에 1의 feature가 담겨 있기 때문에, 1이 들어와도 곧잘 잘 만들어내는 것을 알 수 있었습니다. 이러한 경우, reconstruction error가 크지 않게 되어 결국 anomaly를 detect하는 데에 어려움을 겪게 됩니다. 그래서 본 논문은 우측에 있는 것처럼 어떠한 input이 들어와도 given class의 정보를 생성해낼 수 있게 모형을 디자인하게 됩니다. 그래서 1이 들어와도 결국 8로 생성이 되는 것이지요. 이렇게 되면 재구성 오류가 크기 때문에 anomaly를 잘 detect할 수 있을 것이라는 아이디어가 바로 이 논문이 제시하는 방법입니다.
그렇다면 어떤 방법으로 이렇게 디자인을 수행하는 지, 그 구체적인 방법들을 살펴보겠습니다.
Proposed Strategy
Denoising autoencoder
처음으로 모형의 가장 큰 구조를 이루는 부분은 바로 Denoising autoencoder입니다.
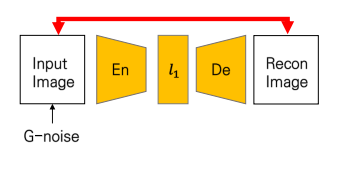
말 그대로 오토인코더인데, input의 가우시안 노이즈를 섞어주는 것이 차이점입니다. 일반적으로 일반 오토인코더보다 노이즈를 살짝 준 이미지를 넣었을 때, 과적합을 줄이고 모형의 generalizability를 확보할 수 있다고 합니다. 저 denoising autoencoder를 바탕으로 계산되는 재구성 오류가 본 모형에서 사용되는 loss function 중 하나가 됩니다. 일반적으로 사용되는 MSE loss를 사용하였습니다.

저기서 l1을 구축할 때, 조밀하게 샘플링을 하기 위해서 마지막 레이어에 tangent layer를 추가해서 (-1,1) 의 범위로 줄여서 latent space를 만들었다고 합니다.
( 원문 : Further, our strategy revolves around densely sampling from the latent space. To facilitate this operation, with the intention of having a bounded support for the latent space, we introduce a tanh activation in the output layer of the encoder. )
Latent Discriminator
다음으로 사용하는 아키텍처는 latent discriminator입니다.

저자는 모든 latent space 상의 instance들이 전부 다 given class를 대표할 수 있게끔 만들고자 하였다고 언급합니다. 그래서 이 in-class의 샘플들이 전부 latent space 상에서 uniform하게 분포시키도록 만들었다고 합니다.
( 원문: The motivation of this method is to obtain a latent space where each and every instance from the latent space represents an image from the given class. We explicitly force latent representations of in-class examples to be distributed uniformly across the latent space. )
즉, distribution을 uniform으로 만들었다는 이야기인데, 이 방법을 수행하는 것으로 GAN의 로직을 사용합니다. GAN의 경우 gaussian noise를 점점 real input의 distribution으로 근사시키는 방법을 수행합니다. 그러한 과정에서 discriminator는 fake와 real를 구분하고 generator는 점차 근사한 distribution을 찾아서 그 샘플들을 만들게 됩니다. 이러한 방법을 이 케이스에 적용하면 real image의 latent space가 갖는 분포를 U(-1,1)인 l2에 근사를 시키는 것으로 생각했습니다. 그래서 다음과 같이 latent discriminator의 loss가 디자인되고, 이는 GAN의 구조와 매우 비슷한 것을 알 수 있습니다.
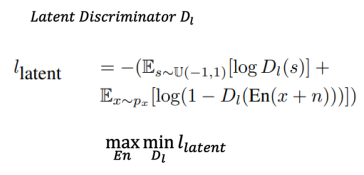
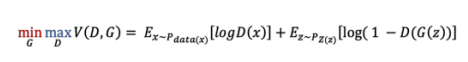
Visual Discriminator
다음으로 사용하는 아키텍처는 visual discriminator입니다.

그렇게 l2에 근사가 되는 샘플들에서, 다시 decoder를 통해 generate하면, 그 이미지는 결국 real image가 갖는 분포와 유사해야 할 것입니다. 여기서도 앞에서 latent discriminator가 사용한 그 방법을 똑같이 사용하게 됩니다. 결국 이 l2의 분포를 real image의 분포에 근사시키는 방법이죠. visual discriminator의 loss function은 다음과 같이 디자인됩니다.

Classifier
하지만 이렇게 구축한 네트워크를 활용하더라도 여전히 given class를 잘 형성해내지 못하는 몇몇 sample들이 존재하였습니다.

예를 들면 위의 (a)에 있는 노란색 박스에 있는 샘플처럼 9를 given class로 학습을 해서 열심히 9로 만들게끔 해도 간혹 0처럼 보이는 샘플들이 만들어지기도 하였음을 언급합니다. 이 이유로는 저자는 latent space 내의 모든 지역에서 학습하는 동안 샘플링을 수행하는 것이 불가능하기 때문이라고 언급합니다. ( 이 부분이 저도 명확하게 이해가 되지는 않았습니다. )
( 원문 : This is because sampling from all regions in the latent space is impossible during training - particularly when the latent dimension is large. )
그래서 latent space 상 일부는 여전히 given class를 잘 만들어내지 못하는 영역이 존재할 수 있다고 하네요. 그래서 이런 space를 찾고 그 space를 given class를 잘 대표할 수 있게끔 업데이트를 해주게 되는데 바로 그 역할을 수행하는 것이 바로 Classifier입니다. 그리고 이러한 샘플들을 informative-negative sample이라고 합니다.
Classifier의 아키텍처는 아래 그림과 같습니다.
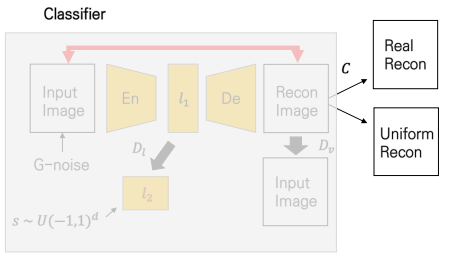
이 Classifier의 핵심 역할은 바로 이 재구성된 이미지가 얼마 만큼 given class와 닮았는 지를 판단하는 것입니다. 이 Classifier는 다른 네트워크들에 앞서 먼저 backpropagation이 이루어지는데, 그 때에 다른 네트워크들의 가중치는 전부 고정이 됩니다. real input 이미지와 uniform distribution에서 뽑은 두 샘플을 바탕으로 학습을 수행하게 되고, classifier는 바로 그 판단의 정확도를 늘려가게 됩니다. 이 때는 binary cross entropy 손실 함수를 사용하게 되고 real이 진짜 real이고 fake가 정말 fake인지를 나타내는 정도가 바로 그 손실 값의 의미가 됩니다. 그리고 이 손실 값을 기반으로 열심히 Classifier는 학습하게 됩니다.

Informative negative mining
이제 이렇게 열심히 학습하고 있는 Classifier를 활용해서 위에서 언급한 informative negative sample들을 찾아 given class를 잘 대표할 수 있게끔 수정하게 됩니다.

그 방법으로는 classifier와 discriminator에 backpropagation을 수행한 다음, 작은 sub-loop를 돌아, 거기서 binary cross entropy를 계산한 다음, 그 gradient 만큼 현재 바라보고 있는 l2를 update하게 됩니다. 이게 무슨 말일까요? 즉 classifier는 real image와 ~만큼 유사하지 않다는 것을, 그 gradient를 도출하게 되고, 그 정보를 가지고 sub-loop에서는 바로 l2를 업데이트를 하게 되는 것입니다. 손실함수는 위의 수식처럼 l2에서 재구성된 데이터와 그 label은 1로서, real이라고 했을 때, 손실이 얼마인지를 보는 것입니다. 만일 '8'이 given class인데 1이 들어오면, 1은 8과는 다른 class이기 때문에 classifier가 8로 보기에는 그 손실이 클 것이기 때문에 큰 gradient를 도출하게 됩니다. 그리고 이 1을 대표하는 latent space를 8을 대표하는 값으로 gradient를 사용하여 update를 하는 것입니다. 그래서 아래 사진의 (b)처럼 이러한 과정을 거치니 조금 더 좋은 샘플들이 나왔다고 하네요.

이렇게 해서 구성된 모형이 OCGAN입니다.
아래는 앞서 이야기드렸던 전반적인 과정을 요약해서 보여줍니다.

여기서 조금 더 주목해볼 부분은 바로, informative negative mining을 마치고 Generator를 update하는 부분입니다. 결국 본 아키텍처에서 generator로서 역할을 수행하는 것은 l1을 만드는 Encoder, reconstructed image를 만드는 Decoder입니다. 이 녀석들이 generator의 loss를 구성하게 되고, 이를 autoencoder를 업데이트하는 데에 필요한 MSE loss를 같이 합쳐 업데이트를 수행하게 됩니다. 저자는 더 질 좋은 output이 나와야하기 때문에 reconstruction loss에 감마 값 (본 논문에선 10)을 붙여 더 업데이트를 잘 수행하게끔 디자인을 하였습니다.
Experiment
본 연구에서는 CIFAR-10, COIL, FMNIST 그리고 MNIST 데이터셋을 사용하였습니다.

Anomaly Detection 실험 환경을 구축하기 위해, one-class setting을 해주어 특정 class 하나를 known class로 잡고 나머지를 out-of-class로 잡아 실험을 수행하였습니다. 이에 대한 실험 결과로는, 우선 CIFAR-10을 제외한 다른 이미지들에 대해서는 다음과 같은 결과가 나왔습니다.

다른 모형들보다 더 outperform한 것을 확인할 수 있었습니다. 하지만 이는 항상 outperform하지는 않았습니다.
저자는 구체적으로 MNIST의 class 별, CIFAR-10의 class 별 anomaly detection 성능을 확인하고자 하였고 다음과 같이 그 결과가 나오게 됩니다.

MNIST는 비교적 모든 class에서 outperform 한 것을 알 수 있지만, CIFAR-10의 경우 상대적으로 그렇지 않은 class들이 있었습니다. 이러한 아쉬운 한계점이 존재하였고 CIFAR-10처럼 배경 사진도 존재하는 그러한 보다 복잡한 feature를 포함하는 경우에서 잘 동작할 수 있게끔 모형을 개선하는 것을 future work으로 제안합니다.
마지막으로 ablation study를 수행하는 데요. 아래와 같이 discriminator를 넣었을 때와 넣지 않았을 때, 한 개씩만 넣었을 때, 그리고 classifer를 넣었을 때를 각각 비교하게 됩니다. 결론은 모두 다 사용한 것이 더 좋은 결과이지만 결과가 큰 차이를 보이지 않아, 다른 데이터셋에도 실험해보면 더 정확히 알 수 있지 않았을까하는 생각이 들었습니다.

이상 OCGAN에 대한 논문 리뷰였습니다. 긴 글 읽어주셔서 감사합니다.



