
No Limitation
[Paper Review] PSD: Principled Syntheyic-to-Real Dehazing Guided by Physical Priors 본문
[Paper Review] PSD: Principled Syntheyic-to-Real Dehazing Guided by Physical Priors
yesungcho 2022. 7. 16. 14:05원 논문 링크 :
Chen, Z., Wang, Y., Yang, Y., & Liu, D. (2021). PSD: Principled synthetic-to-real dehazing guided by physical priors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 7180-7189).
본 리뷰는 제 개인 유튜브 채널에도 올려놓았습니다. 참고 부탁드립니다.
https://www.youtube.com/watch?v=gNBXBC308G0
이번에 리뷰한 페이퍼는 'Image dehazing' task와 관련된 페이퍼입니다. 제가 개인적으로 진행하고 있는 연구와 관련이 있는 페이퍼라 리뷰하게 되었습니다.
"Image Dehazing" 개념에 대해 낯선 분들이 계실 것 같아 초반에는 잠깐 Image dehazing과 관련된 배경에 대해 소개하고 논문의 내용으로 넘어가겠습니다.
Background
What is Image Dehazing?
Image dehazing은 많은 vision관련 task를 푸는 데 큰 도움을 줍니다. 이는 실제 산업 현장에서도 중요한 문제로 작용할 수 있는데요. 아래 그림을 보시겠습니다.

오른쪽의 경우 haze가 없는 이미지, 왼쪽의 경우 haze가 낀 경우의 이미지입니다. 오른쪽과 다르게 왼쪽에서는 bounding box가 정확하게 형성되지 않은 경우를 볼 수 있습니다. 이렇듯, 실제 object detection 같은 task를 수행할 때 image가 noise가 끼게 되면 제대로 사물을 분간하지 못하는 문제가 발생하죠. 이런 경우는 자율 주행과 같은 문제를 풀 때는 치명적일 수 있습니다. 이는 다양한 산업에서 중요한 기술이고 실제 많이 연구가 되고 있는 분야입니다.
다양한 noise 중에서 특별히 'haze' 문제에 다루어보도록 하겠습니다. Haze란 물체로부터 반사된 후에 대기를 통과하면서 일부 손실된 빛과 주변 광원으로부터 시야로 들어오게 되는 대기 산란광(Airlight)이 섞여서 발생하는 현상입니다. 이러한 현상으로 인해 우리 눈에는 뿌연 현상이 나타나게 되는 것입니다. 이를 잘 설명한 이론이 바로 Atmospheric Scattering Model (ASM) 입니다.
저기서 중요한 요소는 바로 haze가 없는 본래 이미지 J와, 대기 산란광 A, 대기 투과율의 정도를 나타내는 transmission map인 t, 그리고 물체와 렌즈 사이의 거리인 d입니다. 이 구성요소로 haze는 설명될 수 있는데요. 구체적인 수식은 아래와 같습니다.
저기서 J, A, t 들로 도출된 haze image가 바로 I입니다. 그리고 대기 투과율 t는 우측의 수식, 즉 지수함수 형태로 정의가 되며, 거리와 산란 계수 β의 영향을 받게 됩니다.
이제 저희의 task는 반대로 저 I와 A, t들을 활용해 J를 도출하는 것이겠죠. 이 ASM 모형이 haze현상을 설명하는 대표적인 이론입니다. 물론 저 구성 요소를 전부 안다면 그냥 ASM으로 dehazing을 해주면 되지만, 안타깝게도 t와 A는 알려져있는 값이 아니기 때문에, 저 녀석들을 추정할 필요가 있게 됩니다. 딥러닝이 유행하기 전, 저 A와 t를 풀기 위해, 다양한 통계 방법들이 등장하였는데 대표적인 방법이 바로 DCP (Dark Channel Prior), CAP (Color Attenuation Prior), ... 등이 있습니다. 이 중 가장 유명한 방법이 바로 DCP인데, 이 DCP는 바로 다음과 같은 사전 지식을 활용해서 haze를 제거합니다.
Prior : Most pixels 'without haze' tend to have very low brightness values of at least one channel among R, G, and B channels
즉, dark channel value라는 것을 정의해서 구하게 되는데 haze가 있는 이미지의 경우는 이 값이 매우 bright하게 나왔지만 haze가 없는 경우는 그렇지 않았다는 겁니다. 구체적인 예시는 아래 그림과 같습니다.
이 DCP는 매우 중요하게 사용되는 전통 알고리즘이기 때문에 구체적인 공부가 필요하신 분들은 이를 잘 정리해놓은 블로그 주소를 공유합니다. 참고하시면 좋을 것 같습니다.
https://hyeongminlee.github.io/post/pr001_dehazing/
[논문 리뷰]Single Image Haze Removal Using Dark Channel Prior | Hyeongmin Lee's Website
안녕하세요. 오늘은 Deep Residual Learning, Guided Filtering, Faster R-CNN 등으로 유명한 Kaiming He의 CVPR 논문인 [Single Image Haze Reduction Removal Using Dark Channel Prior]에 대한 리뷰를 하려고 합니다. 아이디어도 대
hyeongminlee.github.io
하지만 이러한 전통적인 방법은 한계가 있었습니다. 바로 실제 복잡한 real-world 문제를 풀기에는 여러 제한이 있었다는 겁니다. 대표적인 DCP 방법도 하늘이 있는 사진의 경우 그 부분에 대한 haze제거에 여러 한계점을 가지고 있었습니다. 바로 이러한 부분을 극복하는 방법으로 딥러닝을 적용하는 방법이 연구되었고, 특별히 CNN이 각광을 받으면서 ASM과 CNN을 같이 엮는 방법, 혹은 end-to-end로 CNN만 가지고 t나 A를 예측해서 문제를 푸는 방법 등도 등장을 하게 되었습니다.
그래서 이 때 등장한 여러 학습 기반의 dehazing 방법은 크게 '지도 학습' / '준지도 학습' / '비지도 학습' 으로 나뉘게 됩니다. 이 세 카테고리에 대해서는 뒤에서 자세히 소개해 드리겠습니다. 본 포스팅에서 다루게 될 PSD는 준지도 학습에 속합니다.
Loss function & Metric
그렇다면 이를 학습하기 위한 loss function과 inference의 성능을 측정할 metric으로는 어떠한 것들을 사용할까요? 우선 대표적으로 사용되는 loss function을 살펴보겠습니다.
loss function의 경우 supervised learning처럼 haze와 haze-free가 paired 쌍으로 이루어진 경우에는 MSE, 즉 재구성 오류를 기반으로 동작합니다. 기본적인 재구성 오류가 사용이 되며, 추가적으로 Perceptual MSE라는 것이 사용되는데 일반적인 재구성 오류는 원본 이미지 단위에서 비교가 이루어지지만, Perceptual MSE는 feature map level 수준에서 비교가 이루어집니다. 가령 수식으로 표현하면 다음과 같습니다.

오른쪽의 있는 수식은 Perceptual MSE인데요, original input을 x라고 하면, 재구성한 x를 바탕으로 비교하는 MSE와 다르게 네트워크를 통과한 feature map 수준에서 비교를 수행하는 것이 바로 Perceptual MSE입니다. 조금 더 사람이 인지하는 단위에서 비교를 한다는 의미에서 붙여진 이름이라고 하네요.
반면 paired 쌍으로 이루어지지 않은, 즉 label이 없는 unsupervised 상황에서는 조금 다른 loss를 사용하는데 대표적인 예시로 Total Variance Loss와 Dark Channel Loss가 있습니다. 이는 복구한 이미지 자체가 얼마나 인위적이지 않는지, 즉 얼마나 이미지의 손상이 적고 smooth하고 natural한 지에 따라 loss function을 구축하게 됩니다. 가령 Total Variance Loss는 다음과 같이 구성됩니다.
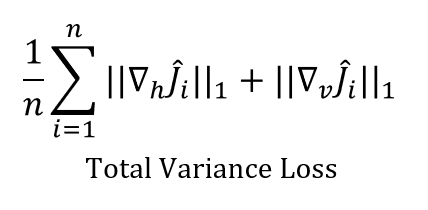
위 수식을 보면 예측한 haze-free 이미지인 J^을 볼 때, 이들의 vertical, horizontal의 gradient 값을 기준으로, 즉 difference를 확인하면서 loss가 구성됩니다. 즉, 구조적이고 세부적인 특징이 잘 보존되고 있는 지를 확인하는 loss라고 볼 수 있습니다.
Metric으로 많이 사용되는 녀석으로는 PSNR과 SSIM이라는 것들이 있습니다. 한번 살펴보겠습니다.

PSNR는 Peak Signal-to-Noise Ratio의 준말로, 해당 이미지의 압축 (예를 들어 .jpeg 같은 파일로 압축을 시킨다고 했을 때 ) 시 발생하는 손실을 바탕으로 주어진 이미지나 영상의 퀄리티를 측정하는 대표적인 함수입니다. 예를 들어 위 수식에서 X를 본래, Y를 압축한 녀석이라고 했을 때, MSE는 그 차이를 나타내는 noise구요, 픽셀 별 할당되는 신호 값을 (2^n-1)^2 로 좌변의 분자 항처럼 정의가 되면, PSNR은 이 잡음 대비 신호의 값을 나타내는 형태로 구성이 됩니다. 이 PSNR은 db단위로 구성이 되며 클수록 이미지/영상의 퀄리티가 좋다고 할 수 있습니다. 보통 30이 넘는 경우 매우 품질이 좋은 것으로 분류된다고 하네요.
SSIM도 비슷하게 압축 시 발생하는 손실의 양을 바탕으로 품질을 평가하는데요. 구체적으로는 휘도나 대비, 그리고 구조적인 특징의 차이를 바탕으로 품질을 평가합니다.

이러한 SSIM은 0과 1사이의 값으로 정의되며 1에 가까울 수록 더 품질이 좋은, 즉 ground truth와 차이가 없는 이미지라고 볼 수 있습니다.
다음으로는 Dataset에 대해 살펴보겠습니다.
Dataset
상식적으로 알 수 있듯 ( haze, haze-free ) 이미지의 동일한 pair 쌍을 구축하는 것은 쉽지 않습니다. 더욱이 outdoor의 이미지의 경우는 여러 이미지의 상황이 바뀔 변수가 존재하기에 동일한 쌍을 얻는 것은 더더욱 어려운 상황입니다. 이러한 상황에서 앞서 배운 ASM 공식을 바탕으로 이런 haze 이미지를 합성해서 pair dataset을 구축하는 방법들이 등장하였고 오늘날 supervised learning에서 많이 사용되는 haze 데이터셋의 대부분은 이러한 합성(synthetic) 방법으로 구성이 됩니다. 구체적으로는 아래 그림처럼 GT와 depth가 있을 때, A와 t를 조절하면서 이미지들을 만들게 됩니다.
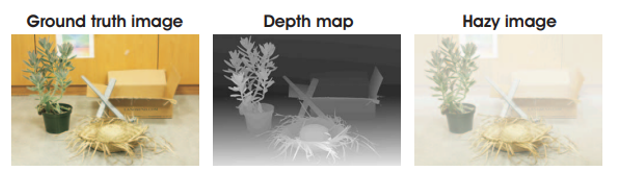
가령 haze 데이터셋으로 많이 사용되는 REalistic Single Image DEhazing (RESIDE) 데이터셋에서는 다음처럼 구성이 됩니다.



또한 haze generator 같은 기계를 동원해 직접 haze를 만들어서 데이터셋을 구축한 경우도 존재합니다.

여기까지 Image Dehazing과 관련한 간단한 Background를 살펴보았습니다. 이제 본 논문의 본격적인 내용을 살펴보겠습니다.
Introduction
앞서 언급드렸듯, Supervised Learning은 바로 아래 그림처럼 GT와 synthetic한 haze-image를 pair 데이터셋으로 사용해서 real data가 들어올 때 inference를 수행합니다. 하지만, 상식적으로 알 수 있듯, synthetic한 데이터와 real data 사이에는 분명 내재적인 차이가 존재하기 마련입니다. 즉, synthetic한 데이터로만 학습을 수행하면 실제 dehaze 문제를 푸는 데에는 제한이 분명 있다는 겁니다.

따라서 이러한 synthetic한 데이터셋과 함께 real data들을 같이 학습을 하는 semi-supervised 방법과 아예 real data 만 가지고 학습을 수행하는 unsupervised 방법들이 등장을 하게 되었습니다. 본 논문은 바로 이 semi-supervised 학습을 진행할 수 있는 generalized한 framework을 제안하게 됩니다.
정말 간단하게 살펴보면 다음과 같은 그림으로 나타낼 수 있습니다.
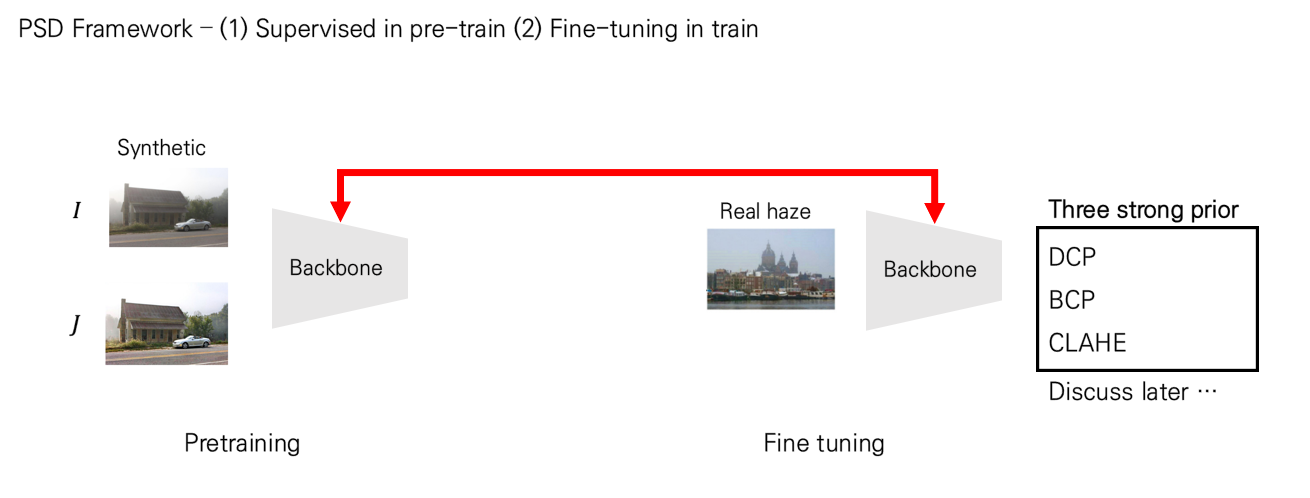
즉, 크게 step을 pre-training과 fine-tuning 으로 나뉘게 되는데요, synthetic한 데이터쌍을 가지고 supervised learning을 수행한 backbone 모형을 바탕으로 real data를 바탕으로 dehazing을 학습할 때 fine-tuning을 함으로써 둘 간의 domain gap을 줄이면서 dehaze task를 더 강화하는 방법으로 아키텍처가 구성되게 됩니다. synthetic 데이터쌍에서는 앞서 언급드린 재구성 오류를 사용하고 unsupervised step에서는 여러 prior (사전 지식)들을 바탕으로 loss를 구성하게 되는데 자세한 사항은 뒤에서 소개해드리겠습니다.
Proposed Method
Pre-train
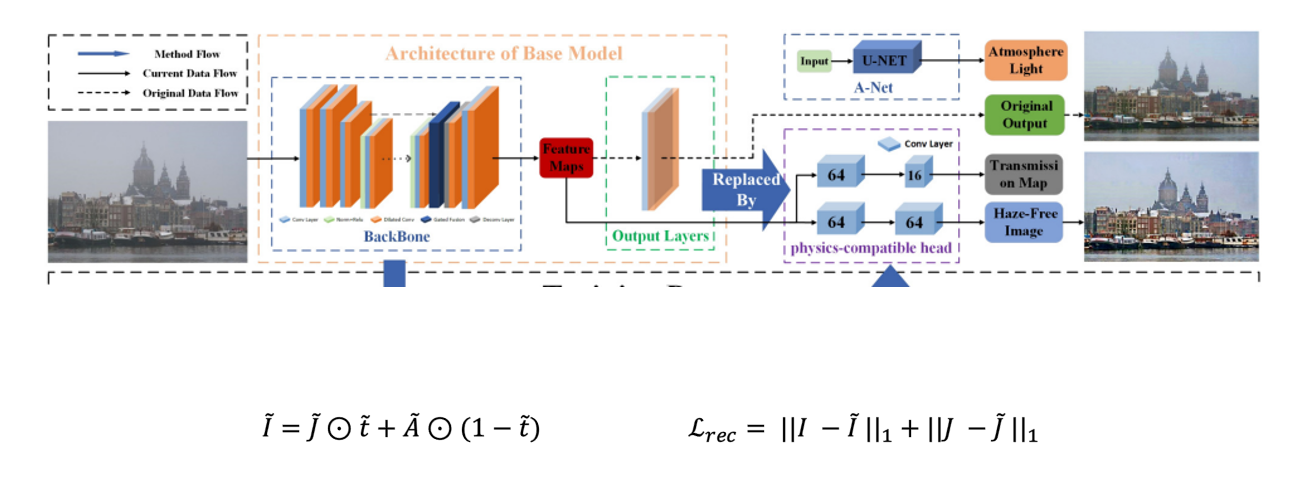
본 논문에 나와있는 PSD의 전반적인 framework입니다. 전체로 보면 조금 복잡해서 저 구성 요소들을 하나씩 뜯어보겠습니다.
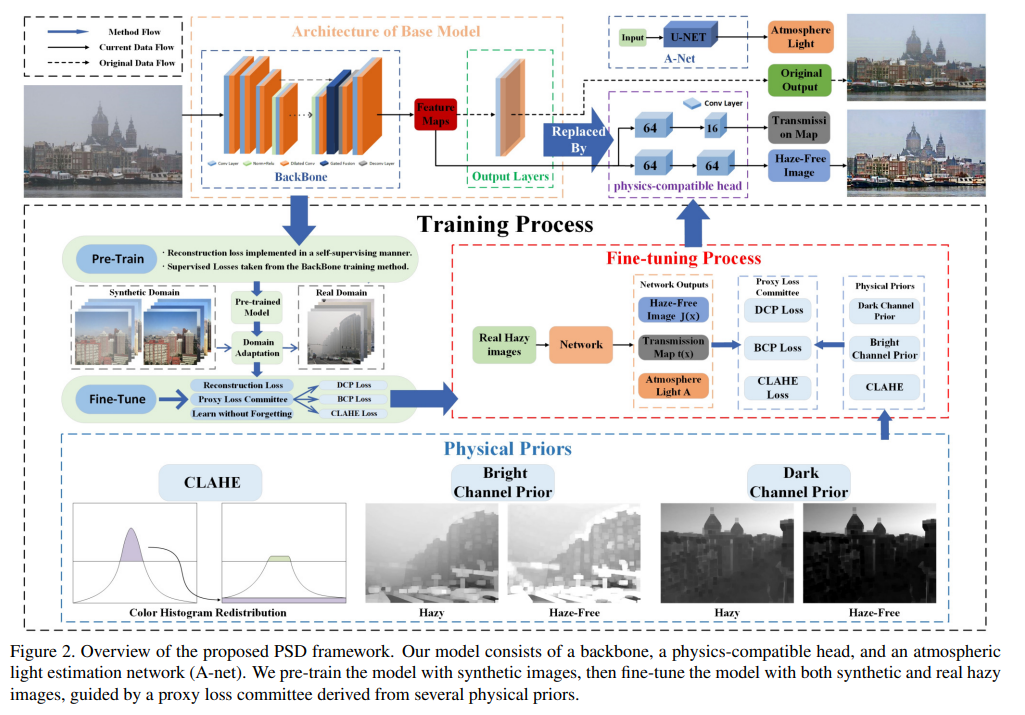
우선, pre-training을 수행하는 부분은 다음과 같이 정의할 수 있습니다.
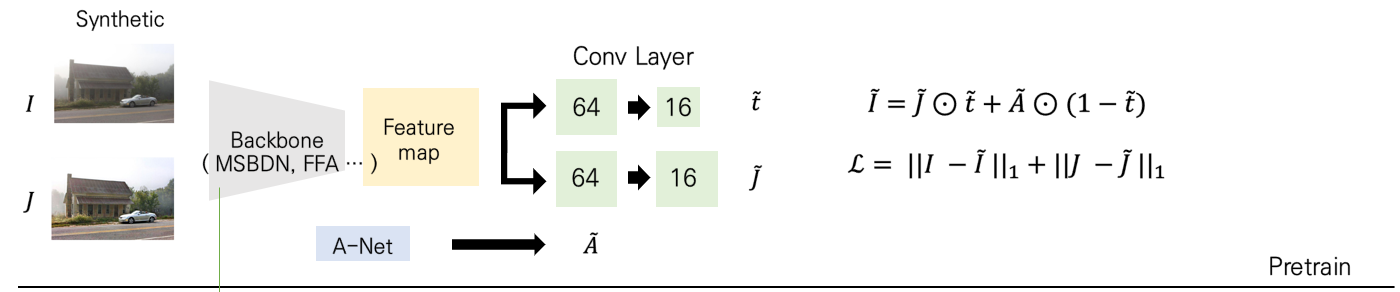
supervised setting에서 dehaze를 푸는 backbone 모형 ( 본 논문에서는 MSBDN, FFA-Net, GridDehazeNet을 사용하였습니다. ) 들을 바탕으로 feature map을 추출하면, 이들 뒷단에 physics-compatible head라는 2개의 convolutional layer를 붙여주어 t와 J에 대한 예측 값을 내놓습니다. 그리고 A-Net이라는 녀석을 별도로 구성해서 A에 대한 예측 값을 도출하여 이들을 바탕으로 haze이미지를 재구성합니다. 그러면 저희는 J와 I의 예측값을 각각 도출하였으므로 각각에 대한 재구성 오류 loss를 구성해서 pre-training을 수행하게 됩니다.
그럼 왜 backbone 모형에서 자동으로 도출되는 형식이 아니라, 굳이 convolution layer를 붙여서 t와 J를 각각 도출하고자 했을까요? feature extractor로서만 backbone을 사용한 이유는 저자가 'generalize한 framework'을 만들고자하였기 때문입니다. 만일 특정 backbone 모형으로 t와 J가 도출되게 되면, 이는 backbone의 성능에 크게 의존하게 되고, backbone 아키텍처마다 디자인을 수정해주어야 하는 번거로움이 있기 때문입니다. 하지만 feature extractor로서만 사용하게 되면 저 자리에 MSBDN이든 FFA-Net이든 뭐든 들어가도 뒷단의 layer로 인해 통일된 형태의 output이 나올 수 있기 때문입니다. 따라서 별도로 physics-compatible head layer를 붙여주었습니다.
또한 A-Net이라는 걸 가져왔는데, 이는 DCPDN이라는 2018년 논문에서 등장한 방법으로 Airlight를 따로 U-Net 모델을 기반으로 추정하는 네트워크를 의미합니다. 구체적으로 DCPDN에 있는 그림을 가져와보면 다음과 같습니다.
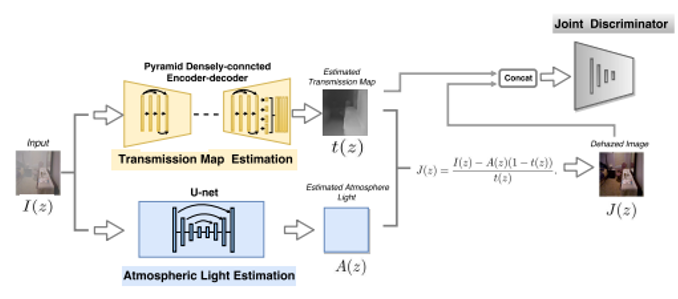
즉 위 그림에서 학습을 수행할 때 t를 도출하는 encoder-decoder 구조와 같이 밑단에는 U-Net 기반의 A를 추정하는 네트워크가 존재합니다. 이를 A-Net이라고 이름하며 이 아키텍처를 PSD도 그대로 가져와 사용하였습니다.

DCPDN 논문에 있는 내용을 더 디테일하게 살펴보면, 'we assume that the atmospheric light map A is homogeneous'라는 언급이 나옵니다. 즉, A가 pixel 별로 다 same value를 갖는다는 것을 말합니다. 조금 특이하죠. 이러한 특징을 가정해서 Airlight을 측정하는 네트워크로서 8-block 의 U-Net 아키텍처를 도입했다고 합니다.
U-Net은 아시다시피 다음과 같은 형태로 구성되죠.
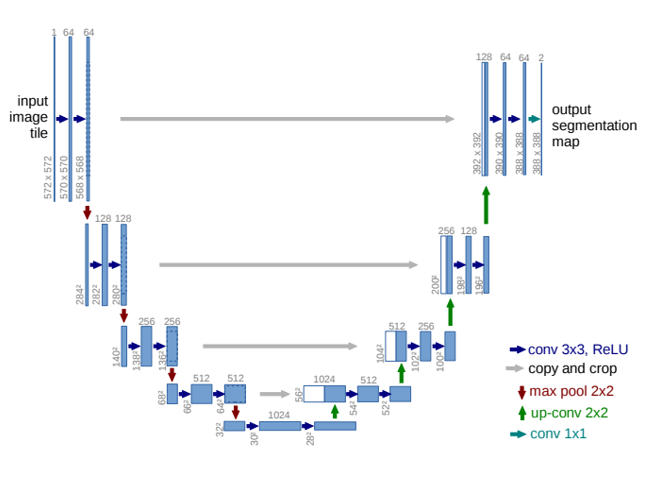
즉 conv layer를 통과하는 feature map과 이후 deconv layer를 통과한 결과와 같이 concat을 수행해주고 다음 상위 level에서 deconv를 수행하는 방식으로 동작을 하게 되죠. 이 과정에서 size를 맞추기 위해 upsampling을 해주는 과정을 거치게 되구요. 이 구조를 바탕으로 우리는 A를 추정하게 되는 것입니다.
따라서 Pre-training 과정에서는 다음과 같이 바로 재구성 오류를 바탕으로 loss function이 구성됩니다.
Fine-tuning
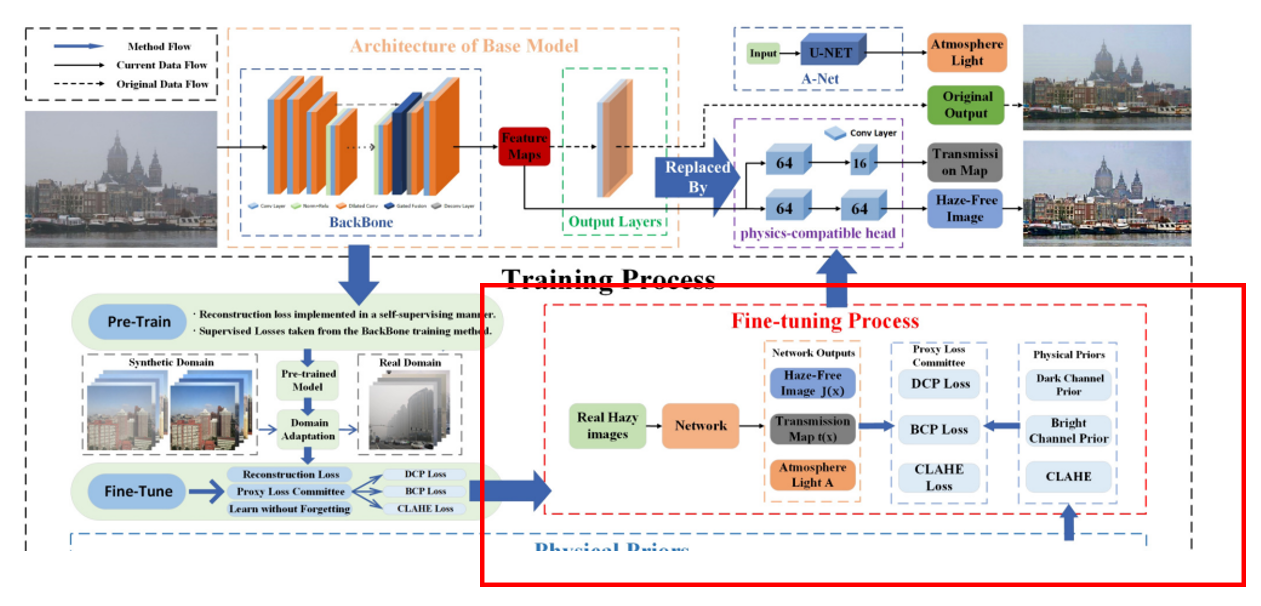
다음으로는 fine-tuning 파트를 살펴보겠습니다.
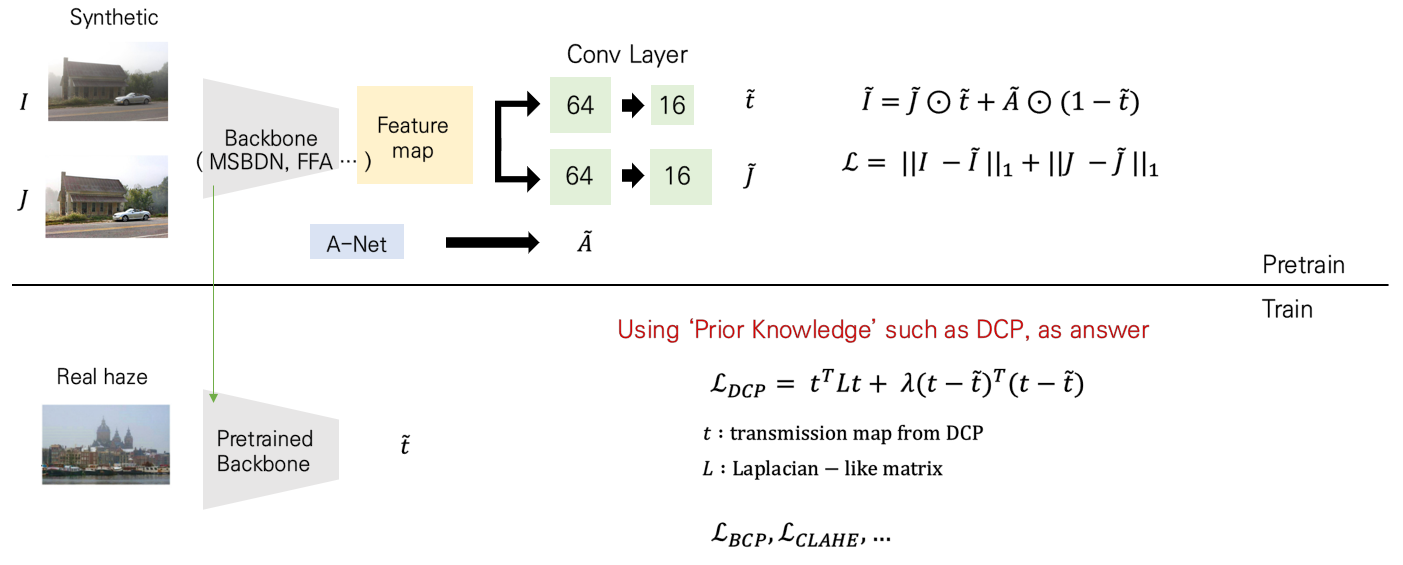
자 위에서 열심히 pre-training을 수행하고 나면, 이제 실제 문제를 풀기 위해 real data를 바탕으로 학습이 이루어져야겠죠. 이 때, 저자는 다양한 loss function들을 도입하는데요. 하나씩 뜯어보겠습니다.
Prior Loss Committee
Prior : Most pixels 'without haze' tend to have very low brightness values of at least one channel among R, G, and B channels
위에서 DCP를 설명할 때 나온 사전 지식입니다. 즉, 이러한 사전 지식들을 사용해서 다양한 loss function을 디자인할 수 있다는 겁니다. 대표적으로 사용되는 것이 앞서 언급드렸던 DCP loss입니다.

하지만 실험적으로 해당 손실함수만 사용했을 때는 dehazing result가 다소 darker한 경향이 있었다고 저자는 언급합니다. 따라서 이를 보완하기 위해 bright한 특징을 바탕으로 구성된 Bright Channel Prior loss를 사용하게 됩니다. DCP랑 살짝 반대 성향을 갖는 loss function이죠.

하지만 둘의 특징은 사뭇 다릅니다.

dark channel value를 구했을 때는 haze-free가 더 어두운 경향, bright channel 관점에서는 더 밝은 경향이 있으니, 이 둘을 같이 loss로 사용하게 되면 balancing하는 부분에서 어려움을 겪는 경향이 있습니다. 따라서 별도의 loss를 추가하게 되는데 이것이 바로 전통적인 dehazing 문제를 푸는 statistics-based 방법인 Contrast Limited Adaptive Histogram Equalization (CLAHE) 입니다. 이는 별도로 dehazing 결과를 내놓는 모형이기에 이 때 예측한 J를 바탕으로 I를 구성해 재구성 오류를 바탕으로 loss를 디자인합니다.

실제 unsupervised 세팅에서 학습할 데이터가 다음과 같은 데이터가 있으면,


CLAHE 모형으로 도출한 CLAHE_3 haze-free 이미지를 같이 학습에 사용하게 됩니다.


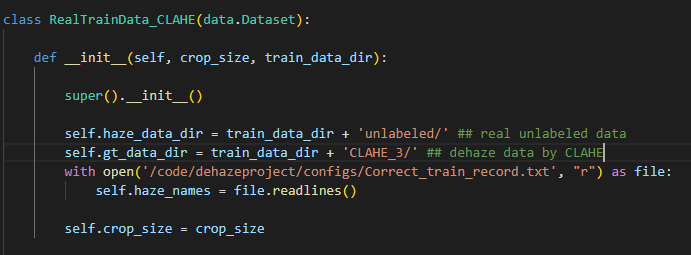
코드를 보면 이들을 같이 한 dataset으로 만들어서 사용함을 알 수 있습니다.
어쨋든 이 셋을 Prior Loss Committee로 구축해서 committee loss를 한 loss로 구축하게 됩니다.
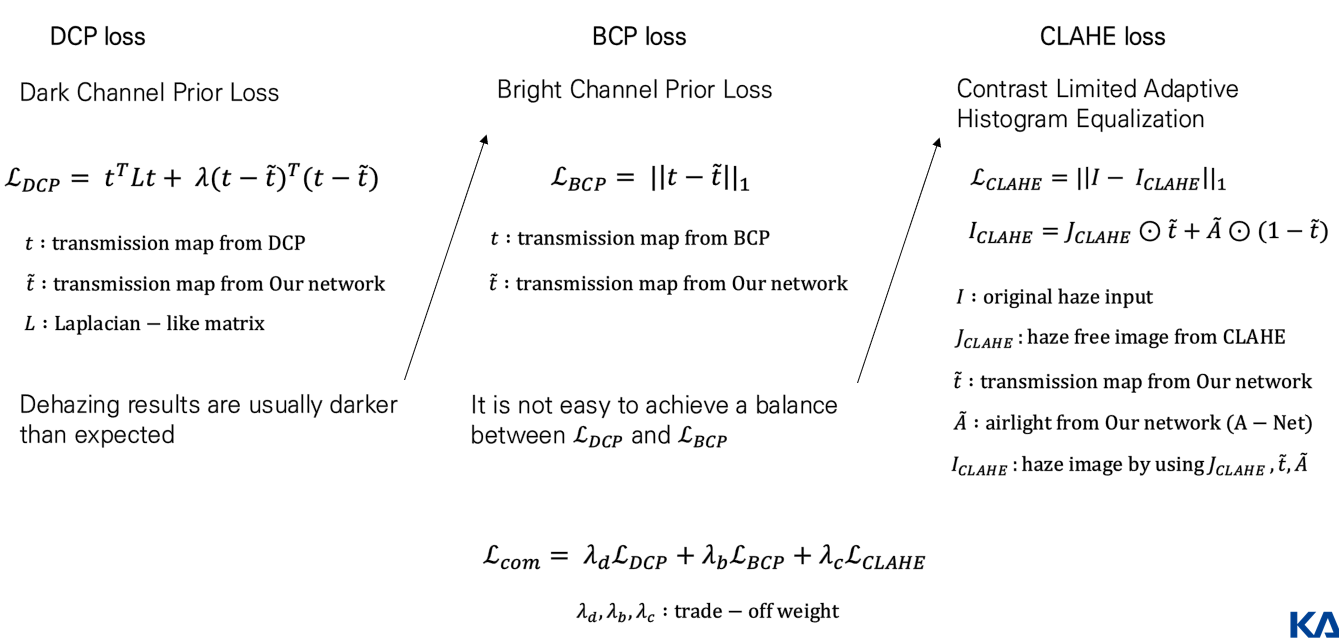
다음으로 'learning without forgetting'이라는 개념을 도입하는데요. 이는 fine-tuning 시, 기존 supervised 학습 시의 기억을 잊지 말라는 의미에서 이들 간의 거리를 감소시키는 방법으로 등장한 논리입니다. 조금 더 디테일하게 설명드리면 아래 그림과 같습니다.
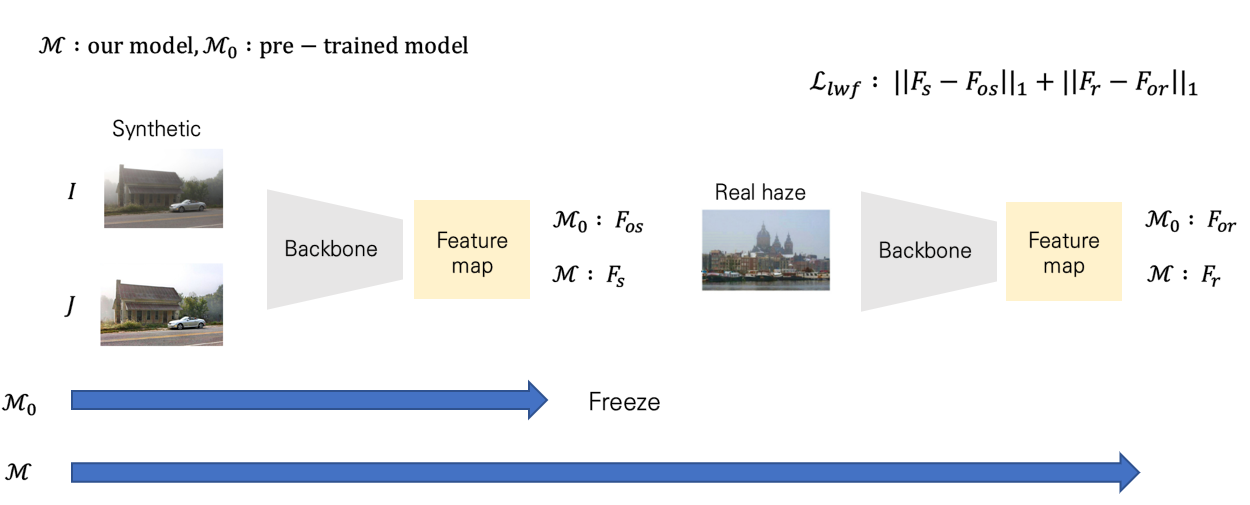
즉, 앞선 supervised 학습을 수행하고 frozen된 모형을 M0, 계속해서 fine-tuning을 수행하는 M이 있다면, 이들이 도출하는 feature map 간의 거리가 커지지 않도록 조절하는 방법으로 동작을 수행합니다. 그래서 그러한 loss도 같이 추가해서 학습을 수행하게 됩니다. Learning without Forgetting(LwF) 개념에 대해 더 디테일한 학습을 원하시는 분은 아래 논문과 블로그를 참고하시면 좋을 것 같습니다.
Li, Z., & Hoiem, D. (2017). Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence, 40(12), 2935-2947.
https://ffighting.tistory.com/entry/LwF-%ED%95%B5%EC%8B%AC-%EB%A6%AC%EB%B7%B0
[PAML 2017] Learning Without Forgetting (LwF) 핵심 리뷰
내용 요약 LwF(Learning-Without-Forgetting) 방식의 Incremental Learning 방법론을 제안합니다. Cross Entropy Loss와 Softmax 출력층에 Distillation Loss를 적용했습니다. 안녕하세요. 오늘은 PAML 2017 논문..
ffighting.tistory.com
이 외에도 sky에 대한 DCP의 한계를 극복하고자 추가적인 loss term을 두어 최종 loss function을 구축한 결과는 다음과 같이 구성됩니다.

다음은 이 아키텍처를 바탕으로 실험한 결과를 확인해보겠습니다.
Experiments
우선 구체적인 실험 환경 설정은 다음과 같습니다.

데이터셋은 앞서 언급드렸듯 RESIDE 데이터셋, 구체적으로 pre-train 시에는 OTS, Fine-tuning 시에는 URHI를 사용하였고, validation 시에는 SOTS(Synthetic Objective test set)를 사용하였습니다.
backbone 모형으로는 dehaze SOTA 모형인 MSBDN, FFA-Net, GridDehazeNet을 사용하였고 당시 가장 퍼포먼스가 좋았던 MSBDN 기준으로 실험을 진행하였습니다. 구체적인 파라미터 셋은 위의 슬라이드를 참고하시면 될 것 같습니다.
( Batch는 12로 디폴트로 되어있었는데 개인적으로 코드를 돌렸을 때, out-of-memory가 계속 발생해서 실제적으로는 4 정도로 사용해야할 것 같습니다... )
Visual Quality
처음으로 저자가 실험한 것은 직관적인 결과의 Quality 보고입니다.


RTTS ( Real-world Task driven Testing Set ) 데이터셋을 기준으로 예측 결과를 확인해본 결과 저자는 다음과 같이 평가했습니다.

NLD, AOD-Net, MSBDN, SSLD, EPDN, DAD 와 같은 dehaze를 푸는 다양한 알고리즘들을 비교실험으로 넣었는데요, 어떤 경우는 dark한 경우도 있었고, 이미지에 왜곡이 되는 경우가 종종 있었지만 PSD는 이들 대비 상대적으로 퀄리티가 좋은 이미지를 도출했다고 합니다.
Human Subjective Evaluation
하지만 이 실험 결과는 다소 객관적이지 못하니 또 다른 실험을 거치는데요. 바로 실제 10명의 피실험자를 대상으로 10개의 데이터셋을 주고 어떤 이미지가 haze-dehaze pair 쌍인 지를 확인하는 실험을 거쳤고, 실제 이 경우도 PSD가 가장 우수한 결과를 보였다고 합니다.
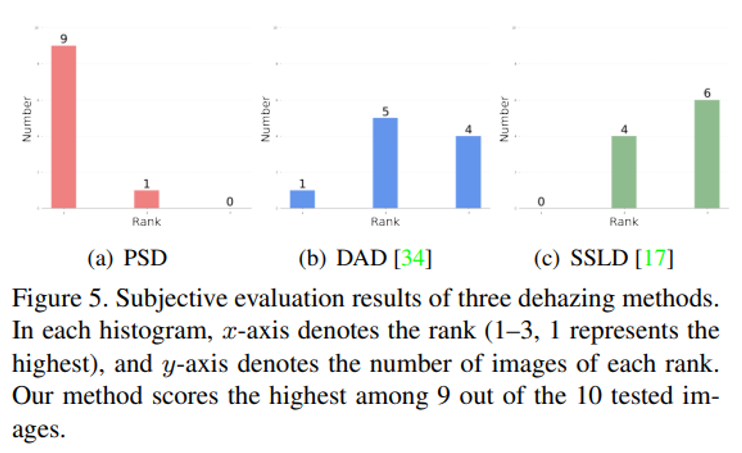
위 그림은 각 알고리즘이 피실험자들이 고를 때 랭킹을 획득한 수를 보여줍니다. x축이 랭킹을 나타내고 첫 번째가 1등, 2번 째가 2등, 세 번째가 3등을 한 횟수입니다. 그래프에서 알 수 있듯, PSD가 1등을 10개의 데이터셋 중 9개에서 1등을 차지해서 사람들이 보았을 때 좋은 이미지라고 평가를 받았다고 저자는 언급합니다.
No-reference Image Quality Assessment
물론 정량적인 비교도 수행하였습니다. 앞서 언급드린 PSNR, SSIM이 아닌 저자는 다른 metric들을 사용하였는데요. 대표적으로 아래 4개의 metric을 사용하였습니다.

FADE의 경우 fog의 density를 판단하는 metric으로 조금 성질이 다르며 대표적으로 BRISQUE나 NIQE가 대표적으로 사용되는 또 다른 품질 평가 metric입니다.
BRISQUE만 간단하게 예를 들어보죠.

상식적으로도, 우리는 일반 사진과 다르게 사람이 합성한 사진은 분명 내재적으로 차이가 있을 것입니다. 바로 이러한 특징을 사용한 것이 BRISQUE 입니다. 여기서는 특별히 mean subtraction and contrast normalization (MSCN) 라는 방법을 사용해서 실제 이미지의 histogram의 분포를 그려보면, natrual image는 MSCN 이후 histogram은 가우시안 분포를 형성함을 알 수 있었다고 합니다. 하지만 natural image가 아닌 경우는 그렇지 않은 특징을 가졌다고 합니다.
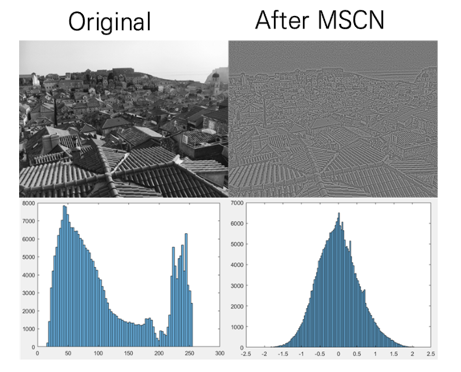
바로 이러한 특징을 사용해서 이미지의 품질을 평가하는 방법이 바로 BRISQUE입니다. 자세한 내용은 아래 블로그를 참고하시면 좋을 것 같습니다.
[IQA] 이미지품질평가 분야의 셀럽, BRISQUE
어떤 컴퓨터비전 분야든지 대표성을 갖는 컴퓨터 모델들이 있습니다. 예를 들어, 이미지 분류에는 ResNet, 객체 검출에는 YOLO, semantic segmantation에서는 FCN, visual saliency에서는 GBVS처럼 말이죠. NR(no-..
bskyvision.com
Task-Driven Evaluation
자 이제, 실제 dehazing이 잘 되었는지 보려면, 이미지 개선 이후 실제 high-level task를 잘 수행하는 지를 봐야겠죠. 대표적으로 저자는 Object detection을 수행하였고 모형으로는 YOLOv3를 사용하였습니다. 이 때, pre-processing으로만 PSD를 사용하였고 joint learning은 수행하지 않았습니다.
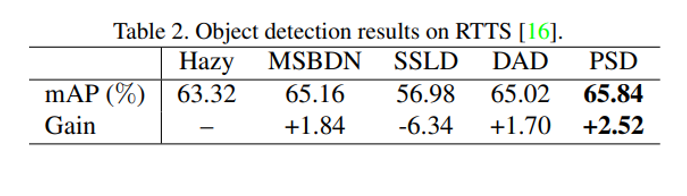
이 때 타 모델 대비 가장 준수한 성능을 보였음을 알 수 있습니다.
Ablation Study
추가적으로 저자는 Prior Loss Committee들에 대한 ablation study를 진행했는데요. 결과론적으로는 세 prior loss들을 다 사용했을 때 가장 natural한 dehaze image가 나왔다고 합니다.

Framework Generalization
마지막으로 저자는 결국 우리가 제안한 모형이 일반화한 framework으로 사용할 수 있는 지를 확인하고자 앞서 언급드린 MSBDN, FFA-Net. GridDehazeNet 모형을 사용해서 성능에 차이가 있는 지를 확인했습니다. 결과론적으로 도출되는 결과에는 아주 큰 차이가 없었음을 언급하면서 일반화한 framework으로 사용할 수 있는 가능성을 저자는 언급합니다.

이상 Image Dehazing에 대한 Intro부터 PSD에 대한 리뷰였습니다! 긴 글 읽어주셔서 감사합니다.



