
No Limitation
[논문 리뷰] A Short Introduction to Boosting, Adaptive Boosting 본문

참고 강의
고려대학교 산업경영공학부 강필성 교수님
https://www.youtube.com/watch?v=HZg8_wZPZGU
Boosting 개념의 시초, Adaptive Boosting에 대해 알아보자
Adaboost에서 우선, 다루어지는 개념은 바로 "Weak Learner"이다.
논문에 보면 다음과 같은 문구가 나온다.

즉, weak model은 random guessing보다는 약간 더 잘하는 모델
예를 들어, 정답이 0/1 2개의 카테고리 변수가 있는 상황에서 이 데이터들이 50% 씩 존재할 때,
어떠한 모델이 60%의 정확도를 가지면
이 모델을 weak leaner라고 한다.
그리고 이러한 weak learner에게 "적절한 가이드"만 주어지면 성능이 향상될 수 있을 것이라고 말한다.

이러한 적절한 가이드를 준다는 것은
"틀린 케이스"에 대해 집중적으로 학습을 수행하는 것을 의미한다.
- 학습 데이터에 대해 weak model 학습
- weak model에 대해 가중치를 다시 결정 → 앞선 모델이 잘 풀지 못하는 케이스에 대해서 잘 풀기 위해
- 조정한 다음 두 번째 weak model을 만듦
- 이렇게 쭉 수행을 해준 다음에 만들어놓은 모델들을 적절히 조합하여 정확한 single predictor를 만들어준다.

이러한 Boosting 방법론은 Bagging과는 다르게, 병렬 처리가 되지 않는다는 특징이 존재한다.
속도도 일반적으로 Boosting이 더 빠르다.
왜냐하면 Bagging의 경우 모델 하나 하나가 의사결정나무나 인공 신경망으로 구성된 경우가 많은데
Adaboost같은 하나의 결정 노드가 존재하는 stump tree로 각각의 모델을 확장해가는 boosting의 전체 모델보다 bagging의 인공 신경망 모델 하나가 더 복잡도가 큰 경우가 많기 때문이다.
다음 그림을 봐보자

우선 기본 weak model을 1차로 학습을 하고 나면 각 스텝이 종료되고 나면
틀린 케이스가 존재하게 된다. 이러한 틀린 케이스에 대해 더 방점을 두기 위해 가중치를 조정하게 된다.
At the end of each round, misclassified examples are identified and have their emphasis increased in a new training set which is then fed back into the next round

위 식과 같이 h≠y 인 경우에 대해서는 가중치를 더 크게 주어 모델에 반영하고 스텝 마다 예측 값을 계산한다.
그리고 그 각각의 순서에 있는 모델들의 결과물을 merge한다.
구체적인 Algorithm Flow를 살펴보자

자 이렇게 되있는 슈도 코드를 하나씩 뜯어보자

우선, 처음에 모델에서 Input으로는
몇 개의 individual한 learner를 쓸 것인지 사전에 정의를 해주어야 한다.
보통 50개~100개 이상 사용한다.

그리고 label에 대해서는 편의상 2개의 label에 대해서만 생각하기로 함
( 지표로는 -1과 1을 사용하는데 그 이유는 뒤에서 설명하겠습니다.)
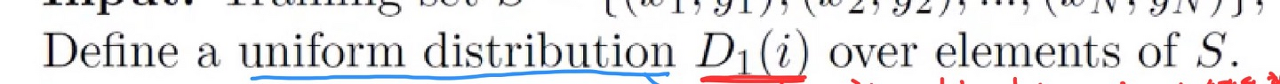
그 다음으로 이 부분 문장을 설명하려고 합니다.
여기서는 D(i)가 의미하는 바가 무엇인지 살펴보면
우선 notation 1은 1번째 step이라고 이해하시면 될 거 같고
D(i)에서 i는 첫 번째 data set의 example i가 선택될 확률, 즉 가중치를 개선할 데이터가 될 확률을 의미하게 됩니다.
그렇다면 처음에는 어떠한 데이터에 가중치를 주어야 할지 판단이 서지 않으므로 모든 데이터에 대해 동등한 권한을 주기 위해 우선 uniform distribution으로 설정하였습니다.
다음 for문을 살펴보겠습니다.

이 부분에 대해서 첫 번째로 각 step이 진행이 되고,
ht가 의미하는 거는 weak model을 의미합니다. 이 모델은 t step에 있는 Dt를 기반으로 학습을 수행하고 2번째 행에서 에러(오분류율)을 계산합니다.
그러면 이 에러를 기반으로 업데이트를 수행해주어야 하는데, 우선 에러가 0.5보다 크게 되면, 그 모델은 상향시킬 incentive가 존재하지 않으므로 그 모델은 제거하고 다른 모델로 적용합니다.
그렇다면 에러 텀이 0.5 미만일 경우, 즉 트리를 더 개선할 여지가 있는 경우는 밑의 행처럼 알파 t라고 하는 항목을 통해 가중치가 계산되는데,
식은 다음과 같습니다.
ln((1-e)/e)/2
예를 들어 살펴보면

에러 값이 0.5에 수렴을 한다는 것은 다른 말로, 저 알파 값이 0으로 수렴함을 의미하고 이는 해당 모델은 가중치를 거의 0으로 둠을 의미한다.
반대로 에러가 거의 0인 경우는 무한대로 발산할 만큼 가중치를 주게 되므로 이 경우는 좋은 모델에는 가중치를 크게 둠을 의미한다.
그리고 for문에서 데이터를 업데이트 하는 수식을 살펴보자

우선 Zt같은 경우는 확률 값으로 부여해주기 위한 normalize factor니까 논의는 생략하고
위 분자 수식을 하나씩 뜯어보겠습니다.

우선 D(i)는 t 시점의 데이터 i의 선택 확률을 의미하고 이를 기준으로 삼습니다.
그 다음, 알파 값은 앞서 말했던 가중치 값인데 이 알파 값이 클수록 t 시점의 모델이 더 정확한 것입니다.
이 경우 데이터의 변동성을 더 크게 합니다.

즉, ht가 정확하게 맞추고 있다면 sampling rate을 증가시키겠다는 의미인데 이는
ht가 잘 맞추고 있으면 → 선택 확률을 낮추고
ht가 잘 못 맞추고 있으면 → 선택 확률을 높이라
라는 의미와 같습니다.
즉 못 맞추는 경우 더 선택할 확률을 높이라는 의미와 동일합니다.
이어서 살펴보겠습니다.

즉, 저 y*h는 잘 맞추는 경우 1, 잘 못 맞추는 경우는 -1이 되는데
왜냐하면 정답 label이 1과 -1로 했기 때문입니다. ( 이 부분이 앞서 말한 것처럼 0으로 하지 않은 이유입니다. )
그래서 이 값이 1이 되면 전체 수식인 Dt+1(i)는 감소하게 되고 이는 곧, 선택될 확률이 감소함을 의미합니다.
반면 이 값이 -1이 되면 Dt+1(i)는 증가하게 되고 이는 선택될 확률, 즉 가중치를 조정할 데이터가 될 확률이 커짐을 의미합니다.
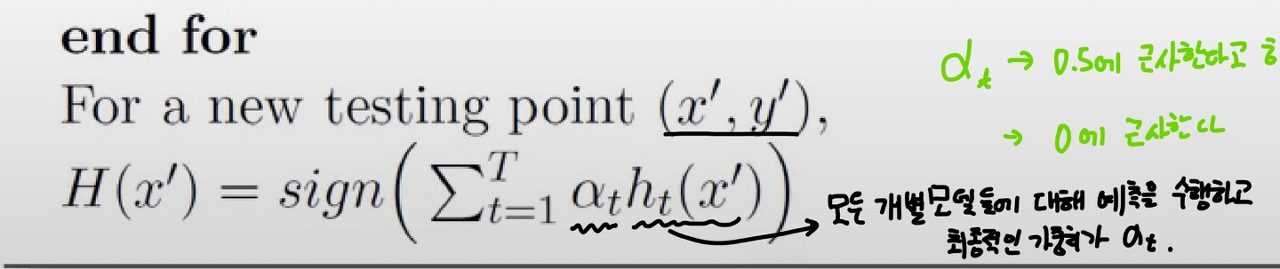
이렇게 쭉 학습을 맞추어준 다음에 새로운 데이터가 들어오면 각 step에 맞는 모델의 예측 결과와 가중치를 곱해준 결과를 합산하여 최종 결과를 도출하게 됩니다.
예시를 들어 구체적으로 살펴보겠습니다.
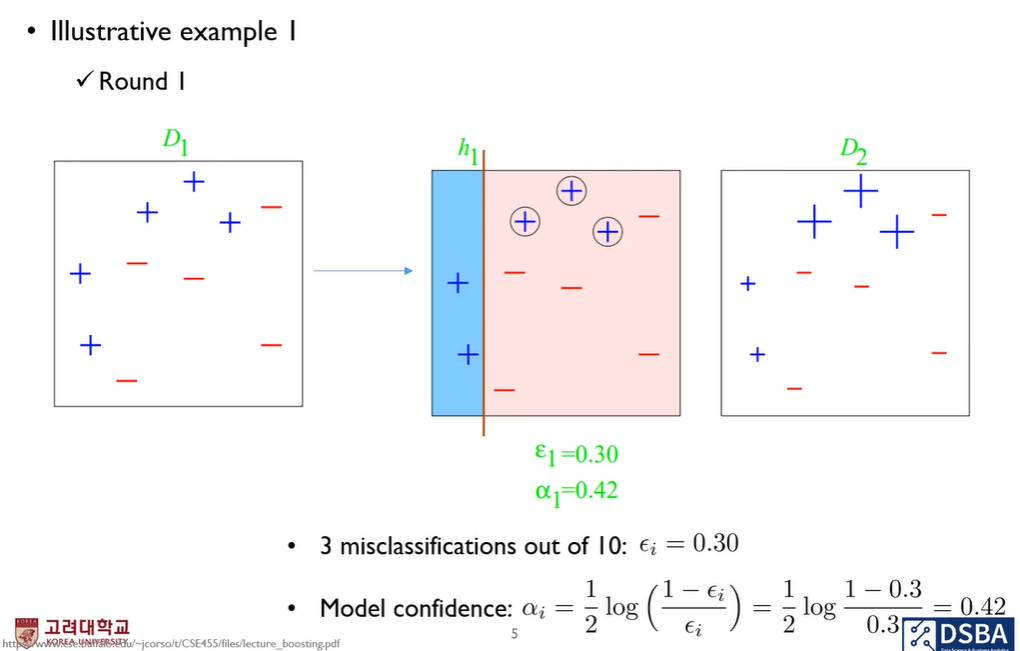
다음 그림에서는 x, y축 2개의 변수를 사용한 경우라고 가정하고 sample들의 크기가 가중치 정도를 의미한다고 생각해보겠습니다.
위선 위 그림의 경우 h1는 처음 stump tree를 구축한 결과이고 그 결과 error는 0.3이 됩니다. 왜냐하면 파란색의 경우는 잘 분류했고 빨간색의 경우가 3개를 잘 분류하지 못했기 때문에 3/10 의 확률이 error가 됩니다.
그리고 이 수식을 기반으로 alpha값을 구하게 되면 0.42가 나옴을 알 수 있습니다.
자 그럼 이러한 값을 기반으로 i 번째 데이터가 다음 가중치 조정의 데이터로 선정되는 확률을 구하는 방법을 살펴보겠습니다.

여기서 i번째 객체의 가중치를 조정하는 방법은 어떻게 이루어지냐면
우선 Case1, 2는 정답을 맞춘 경우니까 다음 stage에서 선택될 확률이 줄어듭니다.

그래서 틀린 케이스의 가중치가 커지고 맞은 케이스의 가중치가 감소하게 됩니다.
이렇게 다음 데이터를 샘플링하는 확률값이 상이해지게 됩니다. (틀린 값 기준)

이러한 부분이 bagging과의 차이라고도 볼 수 있을 것 같습니다.

그 다음 stump tree인 h2를 이용해서도 분류를 수행합니다. 그러고 가중치를 조정해주게 됩니다.

그 다음도 마찬가지로 수행을 해줍니다.
이러한 방법을 계속해서 하면

스텀프 트리 3개를 조합하여 이러한 분류를 수행할 수 있게 됩니다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Neural Machine Translation by Jointly Learning to Align and Translate (0) | 2022.02.04 |
|---|---|
| [논문 리뷰] Sequence to Sequence Learning with Neural Networks (0) | 2022.02.02 |
| [논문 리뷰] Random Forest (0) | 2022.02.02 |
| [논문 리뷰] XGBoost : A Scalable Tree Boosting System (0) | 2022.01.29 |
| [논문 리뷰] LightGBM: A Highly Efficient Gradient Boosting Decision Tree (0) | 2022.01.29 |



