
No Limitation
[논문 리뷰] XGBoost : A Scalable Tree Boosting System 본문

참고 강의
https://www.youtube.com/watch?v=VHky3d_qZ_E
고려대학교 산업경영공학부 강필성 교수님
원문에 대한 자세한 분석은 다음 강의를 참고하자 [추후에 참고]
https://www.youtube.com/watch?v=VkaZXGknN3g
고려대학교 산업경영공학부 석사과정 윤훈상
Decision Tree 기반의 알고리즘이 발전된 순서를 잘 정리해 놓은 도식표를 참고해보자 ( 금일 정리할 XGB까지 어떠한 흐름으로 발전 했는지 )

각각의 설명을 다시 깊게 파헤쳐보자
- Decision Tree
- : A graphical representation of possible solutions to a decision based on certain conditions
- Bagging
- : Bootstrap aggregating or Bagging is a ensemble meta-algorithm combining predictions from multiple decision trees through a majority voting mechanism
- Random Forest
- : Bagging-based algorithm where only a subset of features are selected at random to build a forest or collection of decision trees
- Boosting
- : Models are built sequentially by minimizing the errors from previous models while increasing (or boosting) influence of high-performing models
- Gradient Boosting
- : Gradient Boosting employs gradient descent algorithm to minimize errors in sequential models
- XGBoost
- : Optimized Gradient Boosting algorithm through parallel processing, tree-pruning, handling missing values and regularization to avoid overfitting
XGB는 Gradient Boosting에서, 어떻게 하면 조금 더 빠르고, 대용량의 데이터에 대해서도 처리할 수 있을 지를 해결하기 위해 구상된 알고리즘이다. 즉, Optimized 된 GBM이다 생각하면 됨

다음 6가지에 대해서 최적화가 수행된다.
- Cache awareness and out-of-core computing
- [ 하드웨어 적인 요소라서 추후에 정리하도록 함 ]
- Tree pruning using depth-first approach
- Parallelized tree building
- Regularization for avoid overfitting
- Efficient handling of missing data
- In-built cross validation capability
자 그럼 구체적으로 XGB에서 사용하는 알고리즘들을 하나씩 살펴보자
[1] Approximate Algorithm for Split Finding → 병렬 처리를 통한 시간을 개선!
우선, 기존 Decision Tree는 최적의 split을 찾아주기 위해 어떠한 방법을 사용하냐면, Exact Greedy Algorithm을 사용한다.
다음 그림은 Exact Greedy Algorithm for Split Finding의 알고리즘 flow다.

이 경우는 다음과 같은 장, 단점이 존재한다.
장점 :
항상 optimal split을 찾을 수 있다. 왜냐하면 모든 경우의 수를 다 따지기 때문에
단점 :
대용량 데이터가 메모리에 다 들어가지 않는다면 greedy algorithm 자체를 수행할 수 없다.
또한 모든 경우의 수를 보아야 하므로 분산 처리 환경에서는 처리가 불가능하다.
So, 그래서 이를 Approximate하게 해를 찾는 방법을 적용한다!
Approximate Algorithm for Split Finding의 flow를 살펴보면 다음과 같다.

우선 노랗게 그어 놓은 저 부분을 한번 살펴보자
첫 번째 문장이 의미하는 바는,
변수 k에 대해서 (각각의 변수들에 대해서) 정렬을 시키고,
정렬된 분포에서 percentile을 보고 일정한 갯수 만큼 분할을 수행
( 이 분할의 기준은 epsilon 하이퍼 파라미터에 의해 )
분할한 각각을 bucket이라고 하는데, 위의 경우 { sk1, sk2, .. skl }이 바로 그 bucket들을 의미하고 이 경우는 l개 만큼 존재한다.
이렇게 bucket을 나누게 되면 바로 이 bucket들에 대해 따로 split point를 찾는 과정을 수행하게 된다.
그러면 따로 따로 split point는 어떻게 찾게 될까?
다음 슬라이드를 생각해보자

이 경우 각 데이터는 value 값에 의해 오름차순으로 정렬 (value 값은 편의상 공란으로 해 놓음).
여기서 기존의 Exact Greedy algorithm의 경우는 어떻게 수행하냐면



하나씩 기준 잡아 split 해가면서 graident를 계산하여 ( 이 경우는 관측치 40개에서 39번의 gradient를 수행 ) 가장 gradient가 큰 방향으로(최적화된 방향으로) best split point를 찾음
반면 approximation 알고리즘의 경우?

다음과 같이 10개의 bucket을 구성한다.
그 다음 각각의 bucket에 대해서 gradient를 따로 따로 계산해준다!

예를 들어 1번 bucket의 경우를 살펴보면
각각에서 gradient를 계산해준다



즉, 데이터를 다 사용하는 것이 아니라 해당 bucket의 데이터만 사용하는 거지
그렇다면 정말 빠를까?
Exact Greedy의 경우는 → 39회의 split에 대한 gradient를 계산
Approximation의 경우 → 각 bucket마다 3번씩 * 10회 → 30회
그리고 저 '10회'는 병렬 처리가 가능
( 1번째 버켓 → 쓰레드 1, 2번째 베컷 → 쓰레드 2, ... ) 이런 식으로 각 쓰레드에 연산을 수행하게 되므로, 동시 처리가 가능!
Approximation이 훨씬 빠르게 된다!
단 이러한 장점의 trade off로 best solution을 찾지 못하는 문제가 발생할 수도 있음
자 그럼 다음으로 이 부분을 살펴보자

Bucket을 Approximate하는 데에 있어서
이 작업을
per tree ( 트리 별로 ) → global variant
per split → local variant
단위로 수행할 수 있다.
자 구체적으로 살펴보자
우선 위의 best split point에 의해 pruning된 자녀는 다음과 같다.

이 경우 left child의 bucket은 5개, right child의 bucket은 6개가 된다.
여기서 알 수 있듯이 global variant에서는 트리의 깊이가 깊어지면 깊어질수록 → 탐색해야 하는 bucket의 개수가 줄어듦.
이러면서 bucket 내부에 있는 example의 사이즈는 저 가운데처럼 짤리는 경우를 제외하고는 리프 노드까지 다다랐을 때, 루트 노드에서 유지했던 bucket을 유지하게 된다.
반면 local variant는 어떠할까?
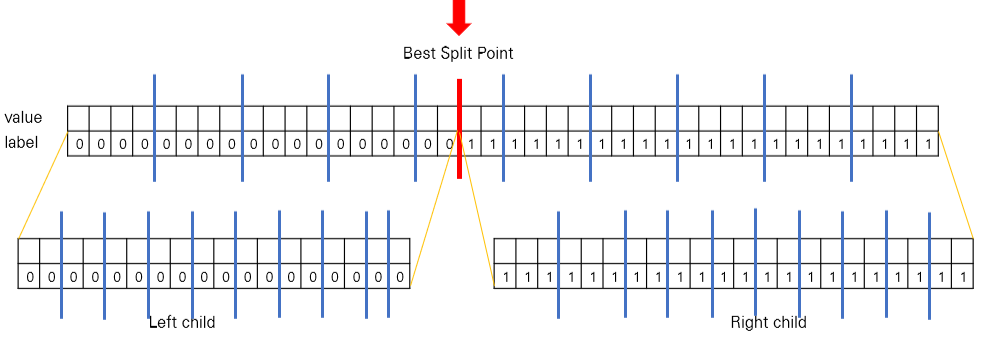
parent bucket에서 size가 10
left child와 right child 노드도 각각의 bucket이 10개
( bucket 수를 유지를 시킴 )
local variant는 split이 계속 되더라도 bucket size는 항상 동일하게 유지가 된다.
= 하나의 bucket에 들어가는 example들의 수는 점차 줄어듦
performance 차이를 비교해보자

eps는 앱실론을 의미하는데, 이 앱실론은 하이퍼 파라미터로서
보통 bucket의 수는 "1/eps" 로 계산된다.
여기서는 exact greedy와 global eps=0.05가 거의 유사함을 확인
또한 여기서 알 수 있는 것은
→ local variant를 쓸 때 보다, global variant를 사용할 때, 훨씬 더 작은 eps를 설정해주어야 한다.
[1] Sparsity-Aware Split Finding → 결측치를 처리!

XGBoost의 또 다른 장점은 결측치를 효과적으로 처리하는 메커니즘
실제 real data set에서는 다음과 같은 문제들이 발생
- Presence of missing values in the data
- Frequent zero entries in the statistics
- artifacts of feature engineering such as one-hot encoding
이런 sparse 데이터에 대해 xgboost의 대응은, Sparse Aware Split Finding
"각각의 split을 구성할 때 각 split마다 default direction(?)을 학습 과정에서 찾아낸다. 그리고 새로운 데이터가 들어왔을 때 어떤 value 값이 NA이면 트리를 구성할 때 정의했던 default direction으로 보내버린다."
이게 무슨 말일까. 예제를 통해 확인해보자.

다음과 같은 데이터가 있다고 하면,
알고리즘이 시작하면서 다음 부분이 시행된다.

결측치가 있는 관측치의 경우 오른쪽으로 다 보내버린다.
그리고 split을 해주기 위한 정렬 과정을 거친다.

다음으로 split을 수행해준다.
이 경우도 하나씩 split마다 gradient를 계산한다.

다음과 같이 연산을 수행해준다.
이 경우는 가장 optimal한 경우는 마지막 케이스이므로 다음과 같이 split이 구성된다.

다음으로 수행하는 연산은

왼쪽으로 결측치를 옮겨준다.

그 다음 여기서도 optimal한 경우를 찾기 위해 split을 구하면 다음의 경우가 된다.

이 경우 위에 파란색 split 기준과 초록색 split 기준을 비교해 보았을 때, gradient의 효과는 초록색의 경우가 더 효과가 컸다.
즉, default direction = left로 설정하는 것이다.
따라서 이 변수에 대해서는 새로운 데이터가 들어왔을 때 missing 데이터가 있으면, 이 경우는 default direction이 left이므로 전부 left로 보내버리는 것이다.
이 경우 위에 파란색 split 기준과 초록색 split 기준을 비교해 보았을 때, gradient의 효과는 초록색의 경우가 더 효과가 컸다.
즉, default direction = left로 설정하는 것이다.
따라서 이 변수에 대해서는 새로운 데이터가 들어왔을 때 missing 데이터가 있으면, 이 경우는 default direction이 left이므로 전부 left로 보내버리는 것이다.
실제 의사 결정 상황에서 어떻게 반영되는 지 보자
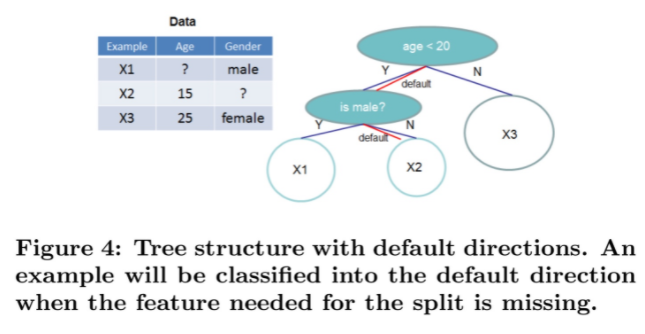
이 경우 Age 변수에 대해서는 default direction이 left이고 Gender에 대해서는 default direction이 right임을 알 수 있다. 따라서 만약 X1의 경우 Age가 missing이면 left로 보내는 것이고 Gender가 missing이면 right으로 보내는 것이다.
밑의 그림은 노멀 케이스와 sparse aware algorithm과의 시간 차이를 비교한 그래프이다.

[3] System Design for Efficient Computing → 정렬 시간을 개선!
for Parallelized tree building
데이터 사이즈가 커질수록, 트리를 학습시키는 데에 있어서 가장 많은 시간이 걸리는 부분은? → 바로 각각의 변수에 대해 정렬시키는 부분이다! O(nlogn) 상당히 cost가 크다
자, 이 문제를 어떻게 해결할까?
데이터를 row wise가 아니라 column wise한 형태로 저장하고, 각각의 컬럼들은 사전이 이미 각각의 feature value에 의해서 sorting한다.
원문 : Data in each block is stored in the compressed column (CSC) format, with each column sorted by the corresponding feature value
잠깐 여기서 column wise가 뭐지?
참고 : https://mjson.tistory.com/182
자 다음 예시를 보자
만일 예를 들어 2x4행렬에 1~8까지의 값을 넣는다고 생각해보자
그러면 자연스럽게 이러한 행렬을 생각해볼 수 있다.
1 2 3 4
5 6 7 8
하지만 이것은 row wise (행 우선 방식) 기반이다.
column wise (열 우선 방식)이 되려면
1 3 5 7
2 4 6 8
이 되어야 한다.
다시 본문으로 돌아와서,
"각각의 컬럼들은 사전이 이미 각각의 feature value에 의해서 sorting한다"
이게 무슨 말일까?
예를 들어
3 2 1 4
7 8 5 6
이렇게 데이터가 구성되어 있을 때, 이를 column wise로 바꾸면
2 1 7 5
3 4 8 6
이렇게 된다는 의미 같은데, 이 경우 column은 정렬
대신 index의 위치가 달라지겠지
이러한 layout을 만드는 것 자체는 트리를 학습시키기 전에 한번만 만들어놓으면 되므로
중간중간 sorting을 할 필요가 x → 시간이 절약!
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Neural Machine Translation by Jointly Learning to Align and Translate (0) | 2022.02.04 |
|---|---|
| [논문 리뷰] Sequence to Sequence Learning with Neural Networks (0) | 2022.02.02 |
| [논문 리뷰] Random Forest (0) | 2022.02.02 |
| [논문 리뷰] A Short Introduction to Boosting, Adaptive Boosting (0) | 2022.01.30 |
| [논문 리뷰] LightGBM: A Highly Efficient Gradient Boosting Decision Tree (0) | 2022.01.29 |



