
No Limitation
[논문 리뷰] Neural Machine Translation by Jointly Learning to Align and Translate 본문
[논문 리뷰] Neural Machine Translation by Jointly Learning to Align and Translate
yesungcho 2022. 2. 4. 13:59

참고 강의 :
jiyang Kang 님의 강의
https://www.youtube.com/watch?v=upskBSbA9cA
본 논문의 등장 배경은 기존 seq2seq의 한계점을 보완하고자 하는 모형이다.

우선 다음 그림은 이전 포스팅에서 사용한 그림이었는데 다음과 같이 중간에
‘Large fixed dimensional vector representation’
이 부분이 바로 인코더에서 마지막 hidden state를 context vector로 사용할 때 그 크기가 기존 input size와 동일한 크기로 고정이 된 것을 의미하게 된다. (학습 시)
조금 더 구체적으로 복습해보면

다음 그림에 해당하는 것처럼 동작을 하게 되는데
인코더에서는 마지막 hidden state에서 도출되는 벡터 값을 기반으로 context vector를 도출한다.
밑의 수식의 의미가 바로 그것을 의미한다.

그리고 이 context vector를 바탕으로 decoder에서 가장 조건부 결합 확률이 높은 워딩으로 번역되어 동작한다. 이 때도 hidden state는 번역이 되는 언어의 맥락을 담고 있는 LSTM에 의해 구축이 된다.

하지만, 입력으로 들어오는 문장은 가변적이므로, 고정된 벡터로 학습하게 될 경우 의미의 다양성을 반영한 번역이 이루어지기 어렵게 된다.
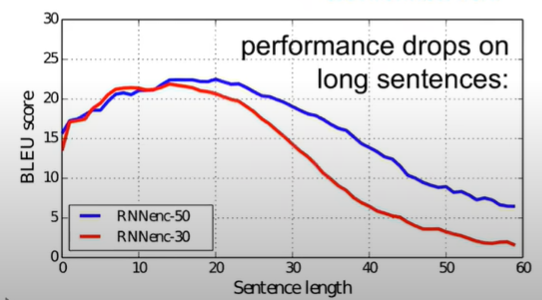
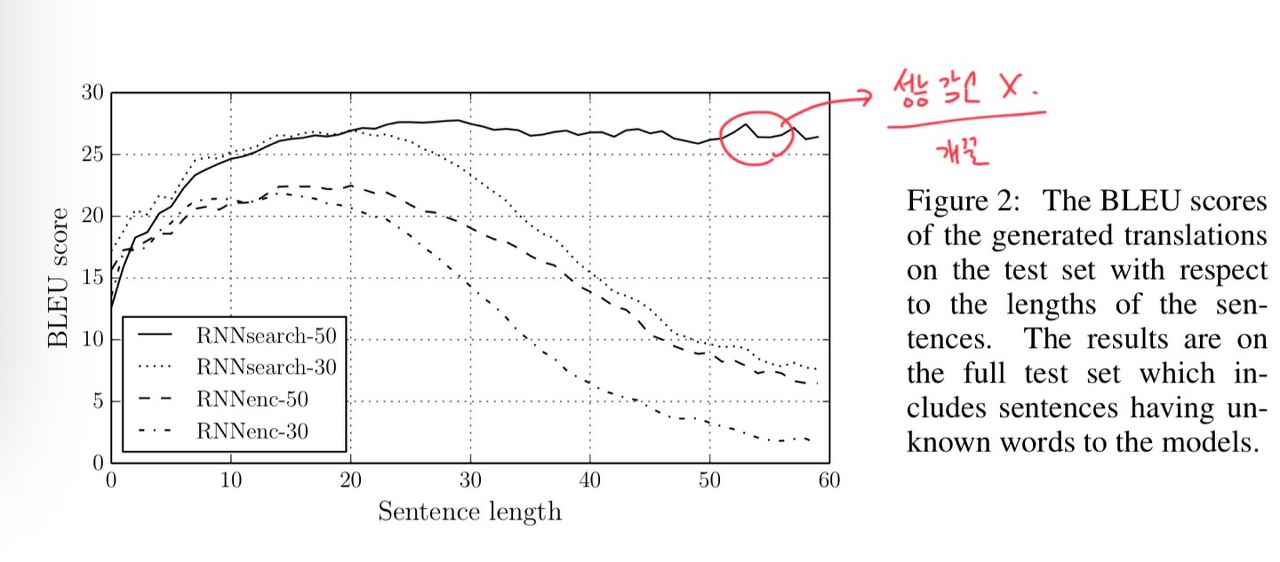
다음 그림의 경우 만일 문장의 길이가 20을 넘어가게 되면 점점 번역의 정확도가 감소하는 것을 확인할 수 있다.
그럼 이 문제를 어떻게 해결하고자 했을까?
본 논문은 ,
기존 seq2seq에서 마지막 hidden state의 1개만 가지고 context vector를 구축하는 것이 아니라 모든 hidden state를 다 살려서 그 친구들의 조합을 활용하여, 주어진 target word (input)과 가장 관련이 있을 것 같은 부분은 어디인지 찾아내는 네트워크를 추가하는 것으로 문제를 해결하고자 하였다.
또한 기존처럼 Translate 모델과 align 모델을 동시에 학습시키는 메커니즘을 이용하였다.
그렇다면 개선한 부분이 어떻게 되는 지를 구체적으로 살펴보자
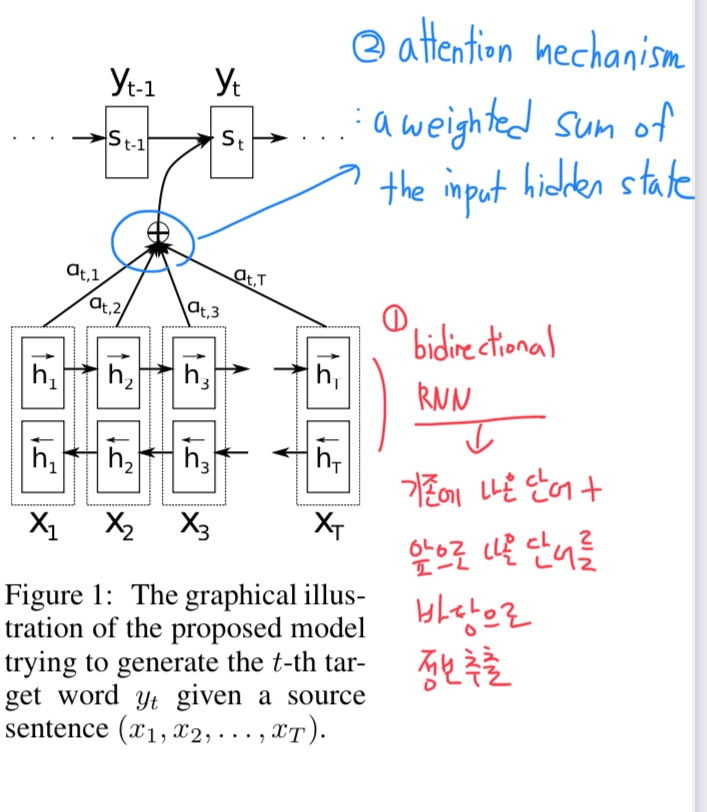
우선 크게 2가지를 개선하였는데
- Using Bidirectional RNN
the hidden state should encode information from both the previous and following words
즉, 기존에 나온 단어들을 통해서만 hidden state를 구축하는 것이 아닌 앞으로 나올 단어에 대해서도 hidden state를 구축하여 거대한 context vector를 만들게 된다.
- Attention Mechanism
a weighted sum of the input hidden state
그리고 구축된 각각의 hidden state의 가중치 합을 만들어 context vector를 만드는 어텐션 메커니즘을 추가하였다.
다음 그림을 참고해보자

다음에서 양방향으로 구축된 hidden state가 맨 오른쪽에 있는 벡터일 때,
이 과정에서 각각의 hidden state를 구축할 때는 주변의, 예를 들어 hj를 구축하기 위해 xj-1, xj, xj+1의 정보를 활용하여 hidden state를 구축하게 되는데 ( 가중치 합으로 ), 이러한 부분에서 가변적인 길이를 반영할 수 있다고 한다.
다음 그림은 앞선 과정을 쭉 정리한 도식도다.

우선 도식도 상에서 i는 각 워드의 index를 의미하게 되는데

이 부분에서 context vector에도 index가 붙는다. 이 말인 즉슨
context vector는 매 워드의 index마다 다시 계산이 수행됨을 알 수 있다.
즉 fixed가 아닌 것이다.
또한 각 가중치는

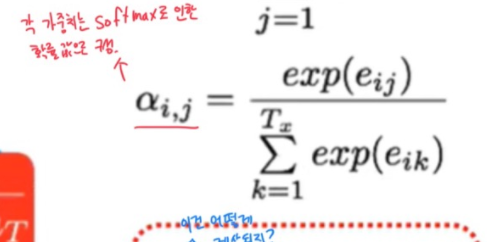
energy 값의 소프트 맥스로 도출되는 확률 값인데
이 energy값이 무엇을 의미하는 걸까?
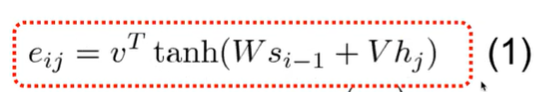
이 energy 값은 출력 값의 hidden state ( 직전 워드의 ) 와 현재 hidden state의 값의 가중치 합을 하이퍼폴릭탄젠트화한, 일종의 작은 신경망 구조로 된 형식으로 계산이 되어 도출된다고 한다.
그리고 저 값은 attention 모델마다 조금 상이하다
그래서 이러한 모형을 적용했을 때 앞선 경우 길이가 길어지면 성능이 감소한 반면
'논문 리뷰' 카테고리의 다른 글
| [Paper Review] Deep Anomaly Detection with Deviation Network (2) (0) | 2022.04.14 |
|---|---|
| [Paper Review] Deep Anomaly Detection with Deviation Network + Anomaly Detection의 개요 (1) (0) | 2022.04.11 |
| [논문 리뷰] Sequence to Sequence Learning with Neural Networks (0) | 2022.02.02 |
| [논문 리뷰] Random Forest (0) | 2022.02.02 |
| [논문 리뷰] A Short Introduction to Boosting, Adaptive Boosting (0) | 2022.01.30 |



