
No Limitation
[Greedy] 신입사원 - 백준 본문
https://www.acmicpc.net/problem/1946
1946번: 신입 사원
첫째 줄에는 테스트 케이스의 개수 T(1 ≤ T ≤ 20)가 주어진다. 각 테스트 케이스의 첫째 줄에 지원자의 숫자 N(1 ≤ N ≤ 100,000)이 주어진다. 둘째 줄부터 N개 줄에는 각각의 지원자의 서류심사 성
www.acmicpc.net
본 문제는 다음과 같다.
(서류) - (면접) 에 대한 각 면접자들의 순위가 나오고
회사는 둘 중 적어도 하나라도 우위에 있는 사람은 전부 다 뽑는다.
즉, 다시 말해, 서류와 면접 둘 다 누군가 자신보다 우위에 있는 사람은 뽑지 않는다는 점이다.
이러한 상황에서 문제를 풀기 위해 처음 생각했던 아이디어는 서류와 면접을 기준으로 정렬을 수행한 다음 필터링을 하는 방식을 차용했다.
예를 들면 다음 예제의 경우를 살펴보자.
7
3 6
7 3
4 2
1 4
5 7
2 5
6 1이 경우 처음 시도한 방법은 두 리스트를 만들고 하나는 서류 점수 기준, 하나는 면접 기준 점수으로 정렬한 리스트를 바탕으로 둘다 절대 우위에 있는 면접자는 채용하지 않는 방식으로 동작하는 알고리즘을 만들었다.

위 리스트에서 예를 들어 (7,3)의 면접자의 경우 서류에서는 꼴등을 했는데 면접에서는 (7,3) 보다 우위에 있는 사람은 2명이었다. 이 면접자를 뽑을 지 결정하려면 해당 면접자보다 서류, 면접 둘 다 우위에 있는 자가 존재하면 이 면접자는 뽑히지 않게 된다.
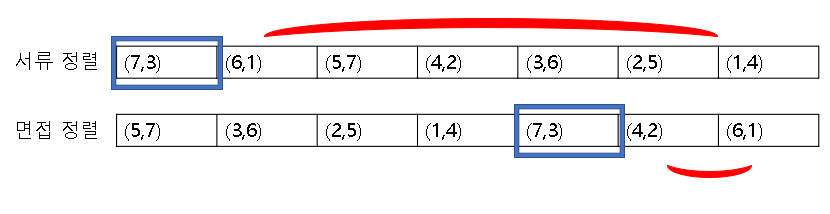
이 경우 (4,2), (6,1)이 중복이 되므로 뽑지 않게 된다.
반면 (4,2)의 경우도 살펴보자.
(4,2)의 경우 서류에서 우위에 있는 사람들은 (3,6), (2,5), (1,4)이고
면접에서 우위에 있는 사람들은 (6,1)이다.
하지만 둘 다 우위에 있는 사람은 없으므로 (4,2)는 채용이 된다.

이러한 방법으로 문제를 푼 코드는 다음과 같다.
N = int(input())
total_list = []
for _ in range(N) :
k = int(input())
lst = []
for _ in range(k) :
first, second = [int(x) for x in input().split()]
lst.append((first,second))
total_list.append(lst)
answer = 0
for i in range(len(total_list)) :
this = total_list[i]
first_judge = sorted(this, key=lambda x : x[0], reverse=True)
second_judge = sorted(this, key=lambda x : x[1], reverse=True)
for j in range(len(first_judge)) :
rest = first_judge[j+1:]
rest2 = second_judge[-first_judge[j][1]:]
if len(rest+rest2) == len(set(rest+rest2)) :
answer += 1
print(answer)
answer = 0하지만 시간 초과가 발생하였다..

분석 결과 총 시간 복잡도는 하나의 채용 케이스에 대해 정리하면
2*nlogn + n*(set변환) 시간복잡도를 갖는다.
이는 통과가 되지 않았다.
그래서 다른 풀이가 무엇이 있을지 찾아보는 중 그리디하게 문제를 푸는 방법이 있었고
이를 공부하기 위해 풀이를 정리해보았다.
참고
https://mygumi.tistory.com/120
백준 1946번 신입사원 [Greedy] :: 마이구미
이번 글은 백준 알고리즘 1946번 "신입사원" 을 다뤄본다. 문제 해결법은 그리디 알고리즘이다. 그리디 알고리즘 - http://mygumi.tistory.com/121 언제나 최고만을 지향하는 굴지의 대기업 진영 주식회사
mygumi.tistory.com
그리디하게 푸는 방법은 다음 메커니즘과 같다.
우선 서류 점수를 기준으로 정렬을 수행해준다.

처음 (1,4) 면접자는 무조건 채용이 되기 때문에 채용하고 시작하고
그 다음 면접자를 살펴본다. (1,4) 기준으로 면접 점수가 높은 직원을 채용하게 된다.

우선 (2,5)를 살펴보면 (1,4)보다 면접 점수가 낮기 때문에 채용이 되지 않고 (3,6)도 마찬가지가 된다.
반면 (4,2)의 경우 (1,4)보다 면접 점수가 높기 때문에 채용이 된다.
그렇다면 다음으로는 (4,2)보다 면접 점수가 높은 직원을 채용하게 된다.

(5,7)의 경우 면접 점수가 낮고 (6,1)의 경우 면접 점수가 높아 채용이 된다.
이러한 방법으로 총 (1,4), (4,2), (6,1) 직원이 채용됨을 알 수 있다.
따라서 이를 구현한 알고리즘은 다음과 같다.
N = int(input())
total_list = []
for _ in range(N) :
k = int(input())
lst = []
for _ in range(k) :
first, second = [int(x) for x in input().split()]
lst.append((first,second))
total_list.append(lst)
for i in range(len(total_list)) :
current = total_list[i]
current = sorted(current,key=lambda x: x[0])
now = current[0]
answer = 1
for j in range(1, len(current)) :
if now[1] > current[j][1] :
now = current[j]
answer += 1
print(answer)
이 경우 시간복잡도는 하나의 채용 케이스에 대하여
nlogn + n의 시간 복잡도를 갖는다.
이 경우 통과가 됨을 확인할 수 있었다.

'프로그래밍' 카테고리의 다른 글
| [ Debugging ] Expected more than 1 spatial element when training, got input size torch.Size([~,~,..]) 문제 다루기 (0) | 2022.07.14 |
|---|---|
| wget 명령어 오류 관련 (0) | 2022.06.15 |
| [Graph] MST - Kruskal Algorithm - 백준 (0) | 2022.02.27 |
| [Graph] Bellman-Ford Algorithm, 최소비용 구하기 - 백준 (0) | 2022.02.26 |
| [구현, 시뮬레이션] 2개 이하로 다른 비트 - 프로그래머스 (0) | 2022.02.12 |



