
No Limitation
[Pytorch] Torchtext 튜토리얼 - '영어' 본문
본 글은 유원준 님의 Pytorch로 시작하는 딥러닝 입문 교재를 참고하였습니다.
자연어 처리 기능을 수행하기 위해 많은 함수를 제공하는 토치 텍스트 모듈에 대해 정리하도록 하겠습니다.
이번 포스팅에서는 '영어'와 관련한 분석을 수행할 때 사용되는 토치 텍스트를 공부하고 다음 포스팅에서는 '한글'을 분석할 때는 어떻게 사용되는 지를 정리하겠습니다.
토치 텍스트는 많은 기능들을 제공하는데 다음과 같은 기능들을 주로 제공합니다.

우선 실습에 사용할 데이터를 로드하겠습니다.
리뷰 데이터이며 리뷰가 긍정이냐 부정이냐를 담는 label이 존재합니다.

전체 샘플의 수는 50000개 이며, 이를 학습 데이터와 테스트 데이터 25000개씩 분할하겠습니다.

토치 텍스트에서는 'Field'라는 도구를 제공하는데, 여기서는 어떠한 전처리 도구를 사용할 것인지를 미리 전제로 합니다. 여기서는 리뷰에 해당하는 TEXT 필드와 레이블에 해당하는 LABEL 필드 2개를 정의하였습니다.

각 파라미터에 대한 의미는 다음과 같습니다.

이제 이러한 필드 구축이 완료가 되면 데이터 로더를 구축하기 위해 데이터 셋을 먼저 구축합니다.


이렇게 구축이 된 데이터셋은 각각 25000개씩 구축이 됩니다.

여기서 직접 구축된 단어들을 확인할 때는 vars 함수를 사용합니다.

이제 이렇게 구축한 데이터셋을 바탕으로 단어 집합(Vocabulary)를 만들어보겠습니다.
그리고 단어 집합을 기반으로 정수 인코딩을 수행하도록 하겠습니다.
우선, build_vocab 메서드를 통해 구축할 수 있습니다.

min_freq : 단어 집합에 추가 시 단어의 최소 등장 빈도 조건 추가
max_size : 단어 집합의 최대 크기 지정
10000개를 최대 사이즈로 선정하였고 구축된 단어 집합을 확인하면 다음과 같습니다.

그리고 총 단어 집합의 길이는 10002개임을 알 수 있는데
이는 단어 10000개에 + <pad>와 <unk>가 추가되었기 때문입니다.
<pad>와 <unk>에 대해서는 지난 포스팅에 언급을 했기 때문에 설명은 생략하겠습니다.

이제 이 데이터셋을 바탕으로 데이터 로더를 정의하겠습니다.
batch_size=5로 설정하여 매우 작은 배치를 구축하여 25000 샘플 / 5 배치사이즈 = 5000개의 배치 수가 구축이 됩니다.

첫 번째에 대한 배치를 확인해보면 다음과 같습니다.
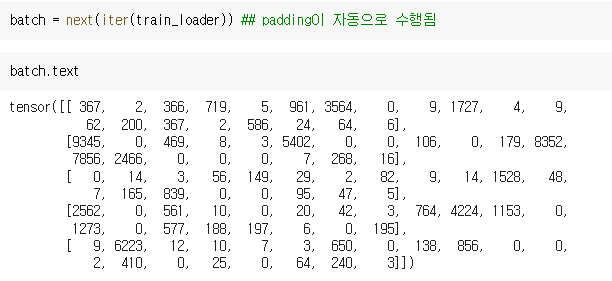
총 5개가 있음을 알 수 있고, padding은 자동으로 수행이 됩니다.
max_length=20으로 했기 때문에 총 20 길이만큼 정수 인코딩이 수행됨을 알 수 있습니다.
'ML & DL & RL' 카테고리의 다른 글
| [Deep Learning] Gradient Exploding Debugging 맨 땅에 헤딩하기 (3) | 2022.04.20 |
|---|---|
| [Deep Learning] Basic Algorithms for Gradient-based Optimization (0) | 2022.04.18 |
| [Pytorch] 자연어 처리 intro - 토큰화와 정수 인코딩 (0) | 2022.03.04 |
| [Pytorch] Convolution Neural Network로 MNIST 분류 (0) | 2022.03.01 |
| [Pytorch] 손글씨 분류 in ANN (0) | 2022.02.27 |



