
No Limitation
[Pytorch] MNIST 데이터 분류하기 - 소프트맥스 회귀로 분류 본문
참고 자료
https://wikidocs.net/53560
유원준 님의 Pytorch로 시작하는 딥러닝 입문 책 자료를 참고하였습니다.
개인적으로 공부하면서 느끼지만
유원준 님께서 정리하신 본 교재는 무료기도 하고 초보자가 pytorch를 입문하는 것을 넘어
머신러닝 개념 자체를 쉽게 정리해주셔서 초보자 분들이 보시기에 좋은 것 같습니다. 추천드립니다
유명한 MNIST 예제를 풀어보는 방법을 구현하겠습니다.
우선 데이터가 어떻게 구성되는지부터 간단하게 소개하면
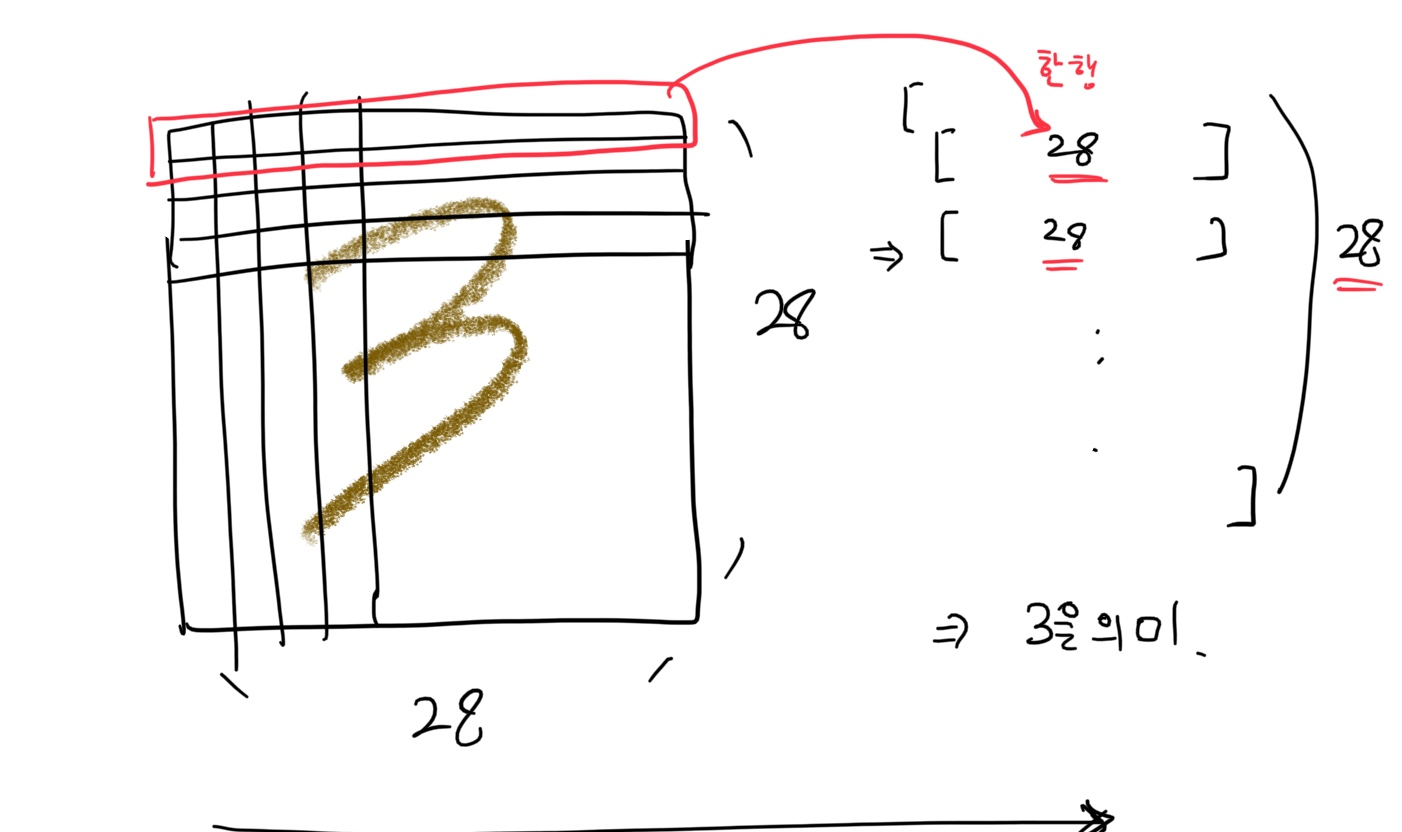
이 부분에 대한 설명을 해보면
우선 '3'이라는 손글씨는 다음과 같이 픽셀로 담기는데 28 x 28의 데이터로 구성이 된다.
이 데이터에서 한 행이 곧 28개의 픽셀이 담기고 이 28개의 행이 총 28개가 있어 한 관측치 당 28*28의 총 784개의 픽셀로 '3'을 구성한다.
즉 이 784개를 하나의 행으로 구성한다.

이러한 관측치가 총 6만개가 있는 데이터가 우리가 사용할 train data가 된다.
이를 코드를 통해 비교하면 다음과 같다.
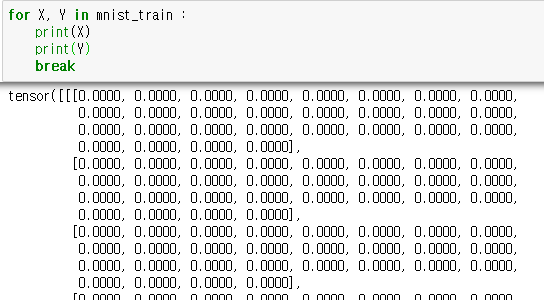
[1] 28*28로 구성된 데이터
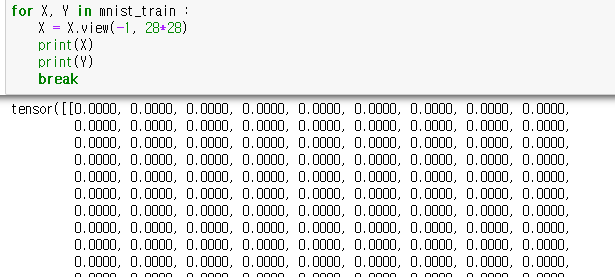
[2] 1*784로 구성된 데이터
우선 모형을 돌리기 전에 실험 환경 설정에 대해 살펴보자

여기서 torchvision이라는 도구는
computer vision에 필요한 여러 도구들, 모형이나 데이터, 전처리 도구들을 포함하고 있다.
참고로 자연어 처리를 위해서는 torchtext 라는 도구가 있다.
Pytorch에서 기본적으로 설정하는 것은
현재 환경에서 GPU 연산이 가능한 지 여부이다.

프로세서에 대한 정의가 가능한 것이 Pytorch가 갖는 매우 큰 장점이다. (GPU)
이후 random.seed와 epoch, batch_size에 대한 기본적인 세팅을 마무리한다.

이제 학습 데이터와 테스트 데이터를 살펴보자

다음 코드를 보면, torchvision에 있는 도구들을 로드하는 방법에 대해 나와있다.

다운로드가 완료되면 다음과 같이 데이터셋 형태로 데이터가 불러와짐을 확인할 수 있다.
이제 Pytorch에서 batch_size와 shuffle 등을 적용하기 위해서 데이터로더 형태로 데이터를 변형해준다.
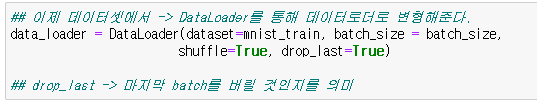
여기서 이전 챕터에서 공부하지 않은 내용으로 'drop_last'가 나오는데,
drop_last는 마지막 batch를 버릴 지 여부를 의미한다고 한다.
예를 들어 1000개의 데이터가 있을 때, batch_size를 128로 하면 7개의 서브 데이터가 나오고
104개의 데이터가 남게 된다. 바로 이 104개를 학습에 쓸지 버릴지를 정하게 된다.
이러한 마지막 batch를 버리게 되면, 이 batch가 Gradient Descent과정에서 상대적으로 과대평가되는 현상을 막을 수 있다.
이러한 틀을 바탕으로 학습 모형을 다음과 같이 구축할 수 있고

손실 함수와 optimizer를 설정할 수 있다.

이런 모든 setting이 완료되면 학습을 수행한다.
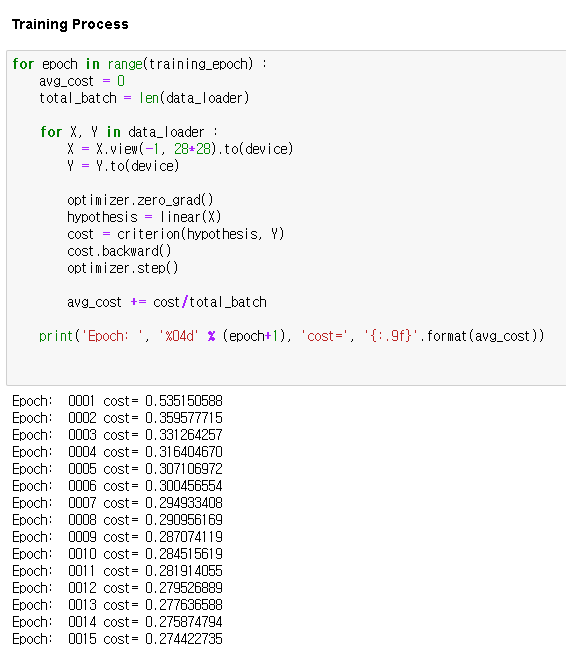
linear 모형을 학습한 다음, 제공받은 테스트 데이터에서 예측을 수행해보자

우선 해당 코드에서
with torch.no_grad()의 의미는
gradient 계산을 수행하지 말라는 의미로 보통 테스트를 수행할 때 사용한다.
그리고 테스트 데이터를 불러온다음
prediction을 수행해주는데
prediction에서

다음과 같은 값들이 존재하는데 첫 번째 관측치에서
[ 218.3591, -2471.1321, ..., 791.0421 ] 이 수치는 각 0~9까지 수에서 부여된 소프트맥스 값을 의미하고 이 중에 가장 큰 소프트 맥스 값이 예측 결과이므로 torch.argmax를 통해 가장 높게 예측한 것을 예측 결과로 부여한다.

그리고 이 부분은 랜덤으로 아무 수나 뽑아보면서 실제 예측이 잘 수행되는 지를 체크하는 코드고

이미지를 출력해보니 8이 정답이었지만 예측은 3으로 해 예측이 틀린 결과가 나옴을 알 수 있다.
학습한 모형은 88%의 정확도를 가졌다.
MNIST는 너무 유명한 예제지만 데이터가 구성되는 방법부터 Pytorch를 이용한 모델을 빌딩하는 작업을 익히도록 하자.
'ML & DL & RL' 카테고리의 다른 글
| [Pytorch] 손글씨 분류 in ANN (0) | 2022.02.27 |
|---|---|
| [Pytorch] XOR Perceptron 구현하기 (0) | 2022.02.21 |
| [Pytorch] 다중 클래스 분류 회귀 (0) | 2022.02.04 |
| [Pytorch] 로지스틱 회귀분석 (0) | 2022.02.04 |
| [Pytorch] Custom Dataset (0) | 2022.02.03 |



